Qu'est-ce qu'Amazon SageMaker Clarify ?
Les avantages de SageMaker Clarify
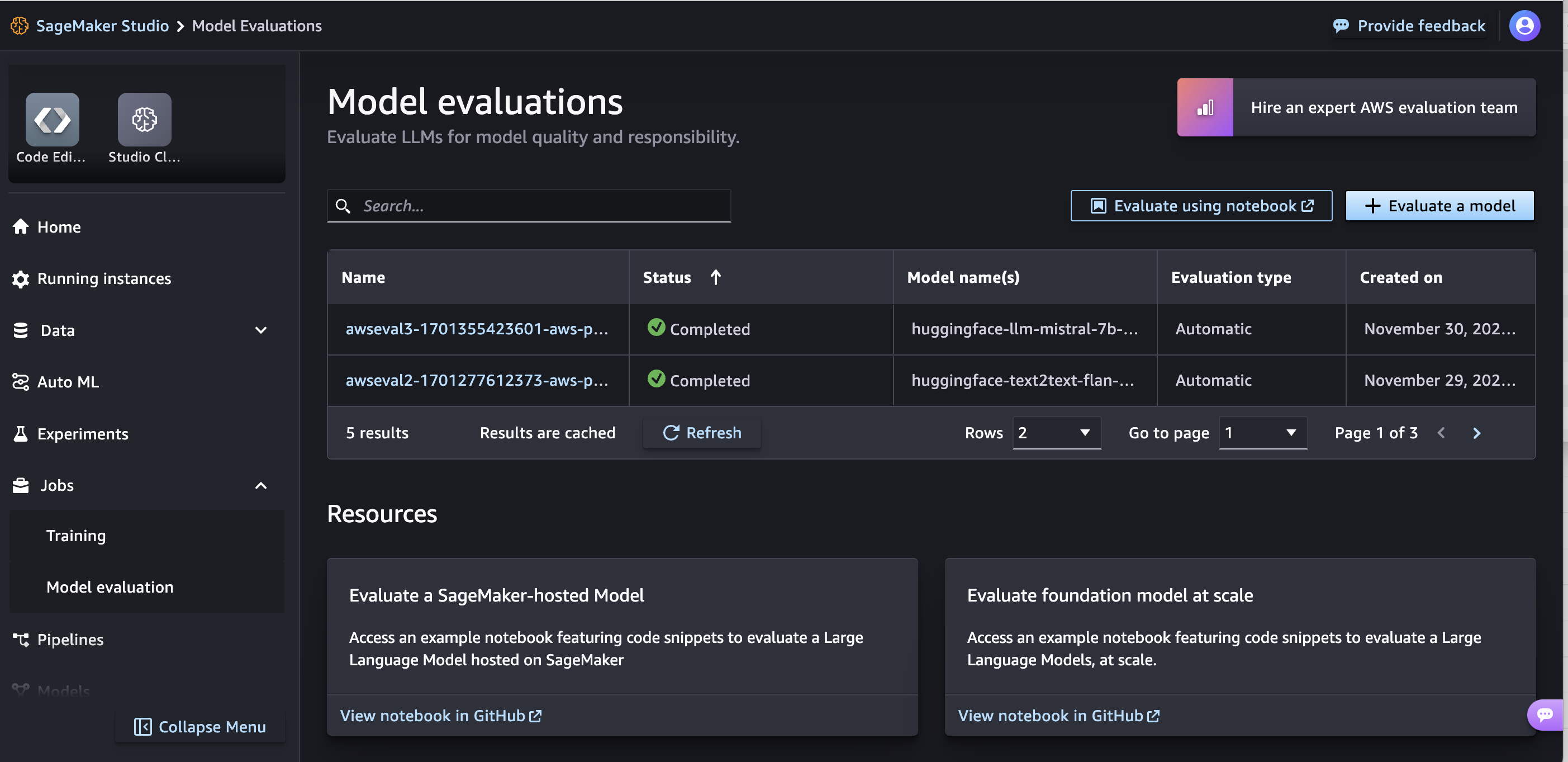
Évaluer les modèles de base
Assistant d'évaluation et rapports
Personnalisation
Évaluations fondées sur l'être humain
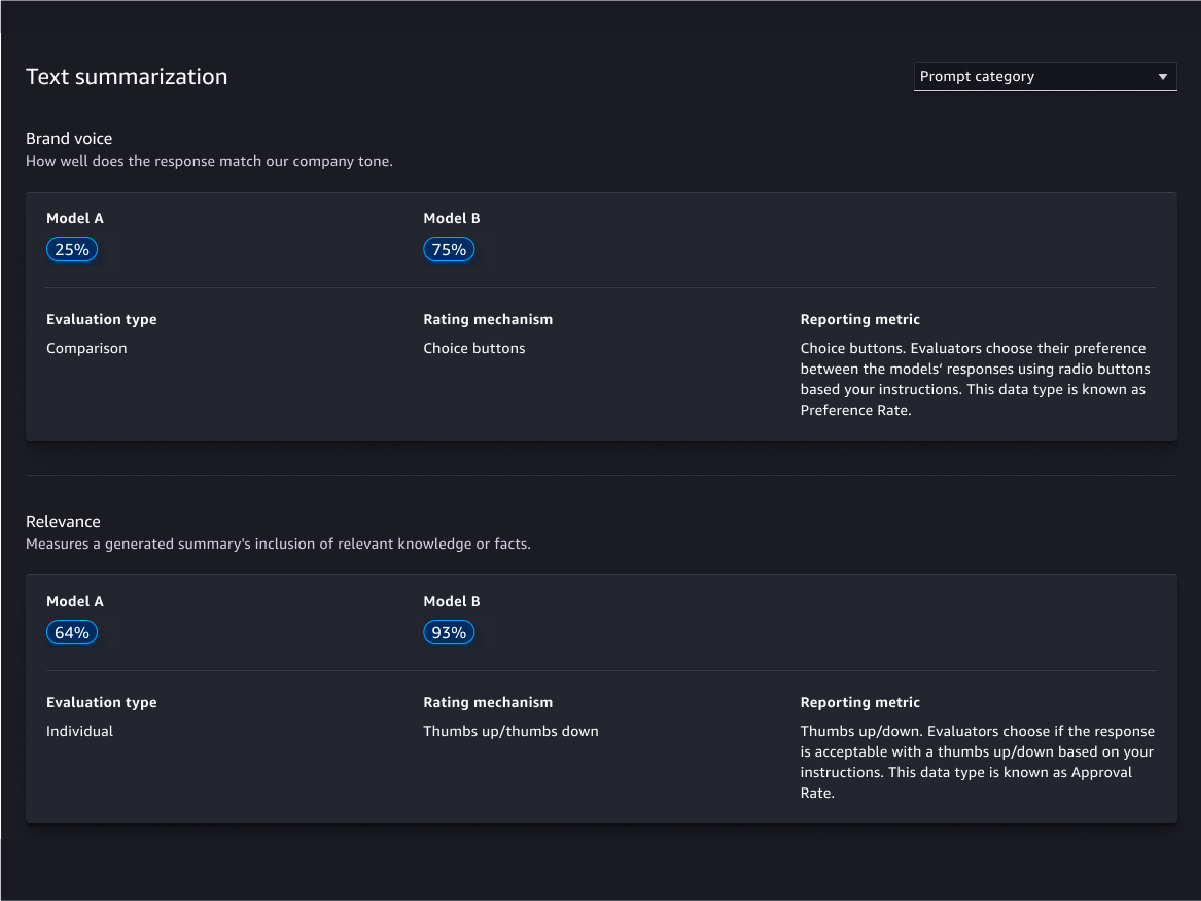
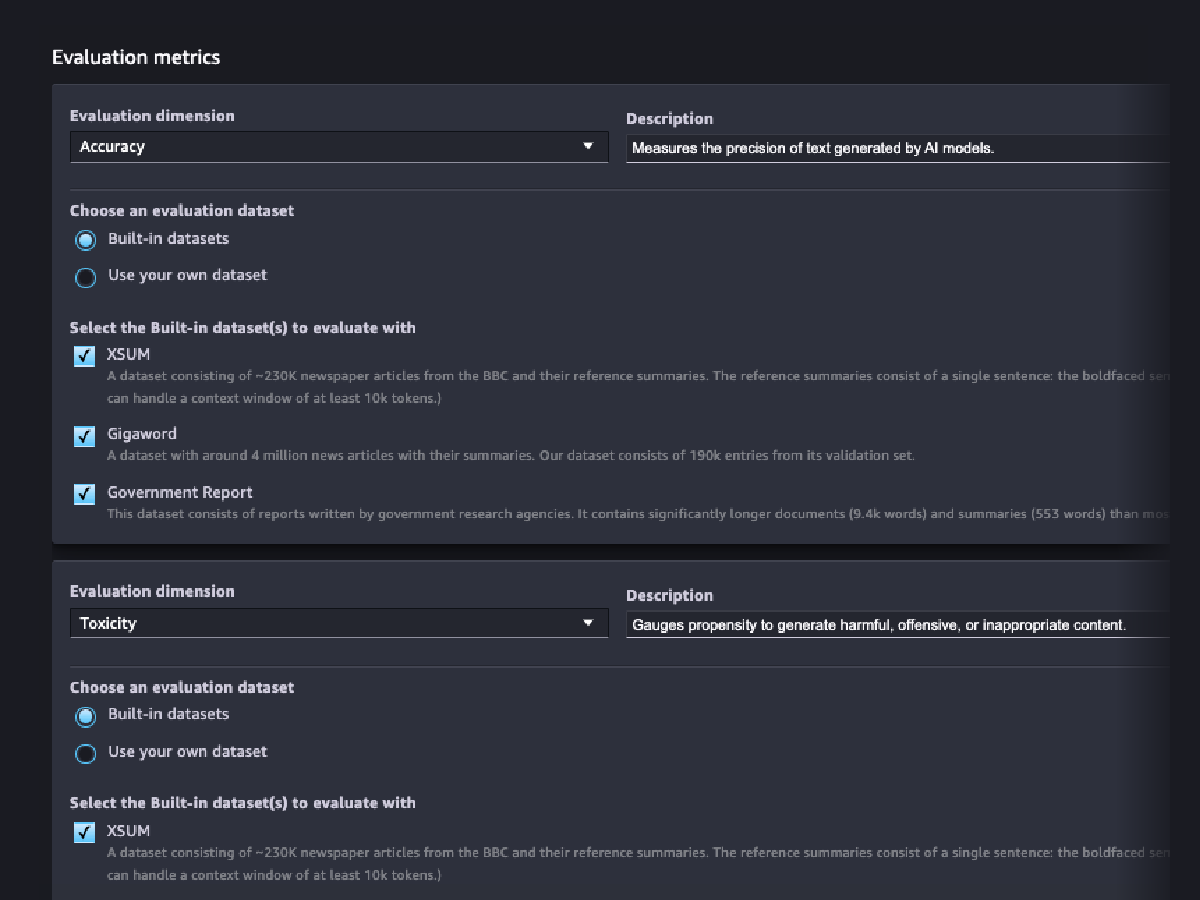
Évaluations de la qualité des modèles
Évaluations de la responsabilité des modèles
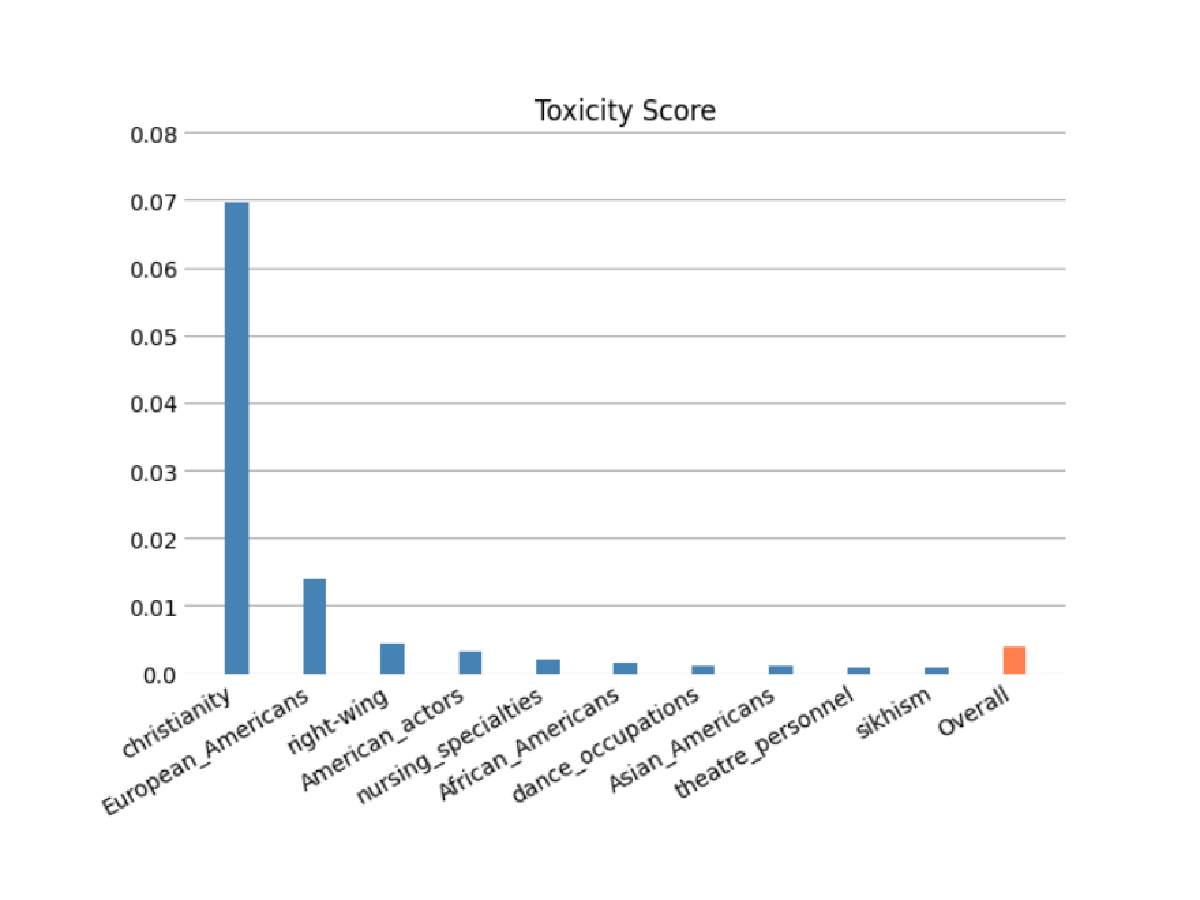
Évaluez le risque que votre FM code des stéréotypes liés aux catégories de race/couleur, genre/identité de genre, orientation sexuelle, religion, âge, nationalité, handicap, apparence physique et statut socio-économique à l'aide d'évaluations automatiques et/ou humaines. Vous pouvez également évaluer le risque de contenu toxique. Ces évaluations peuvent être appliquées à toute tâche impliquant la génération de contenu, y compris la génération ouverte, la synthèse et la réponse à des questions.
Prédictions du modèle
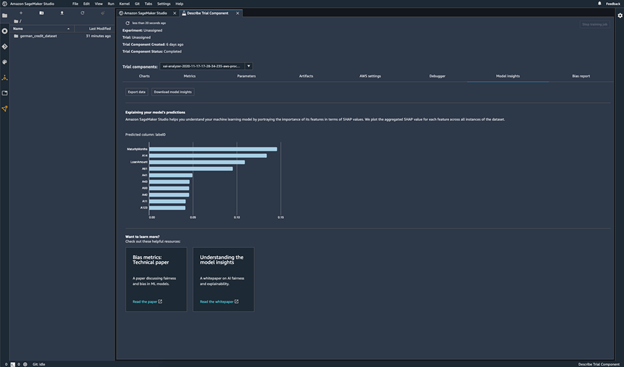
Expliquer les prédictions du modèle
Surveillances des modifications de comportement de votre modèle
Détecter les biais
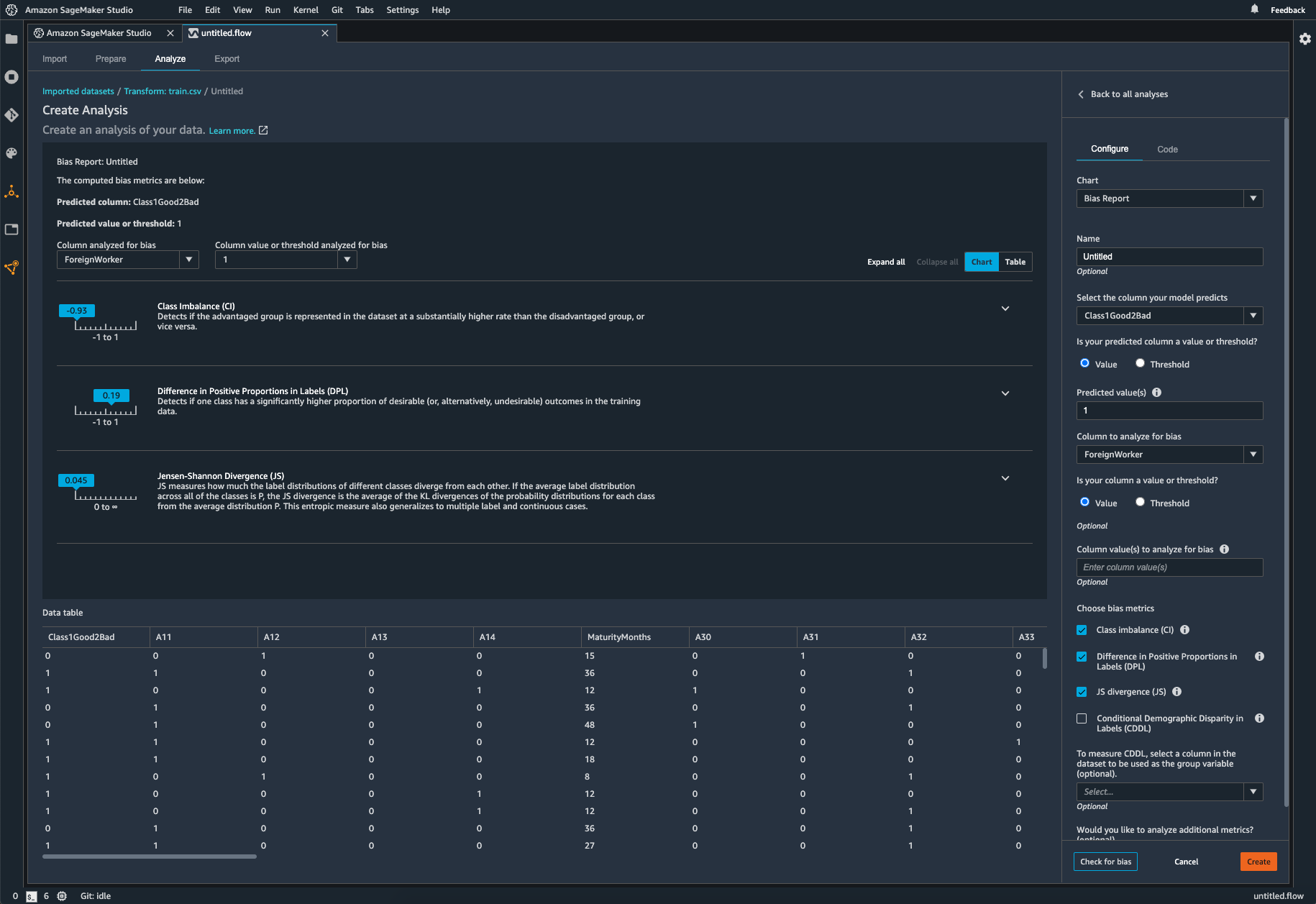
Identifier les déséquilibres dans les données
SageMaker Clarify permet d'identifier les biais potentiels lors de la préparation des données sans écrire de code. Vous spécifiez des caractéristiques d'entrée comme le sexe ou l'âge, et SageMaker Clarify exécute une tâche d'analyse pour détecter les biais potentiels dans ces caractéristiques. SageMaker Clarify présente alors un rapport visuel avec une description des sources et des mesures de biais possibles afin que vous puissiez identifier les étapes pour remédier au biais. En cas de déséquilibres, vous pouvez utiliser SageMaker Data Wrangler pour équilibrer vos données. SageMaker Data Wrangler propose trois opérateurs d'équilibrage : sous-échantillonnage aléatoire, sur-échantillonnage aléatoire et SMOTE pour rééquilibrer les données dans vos jeux de données non équilibrés.
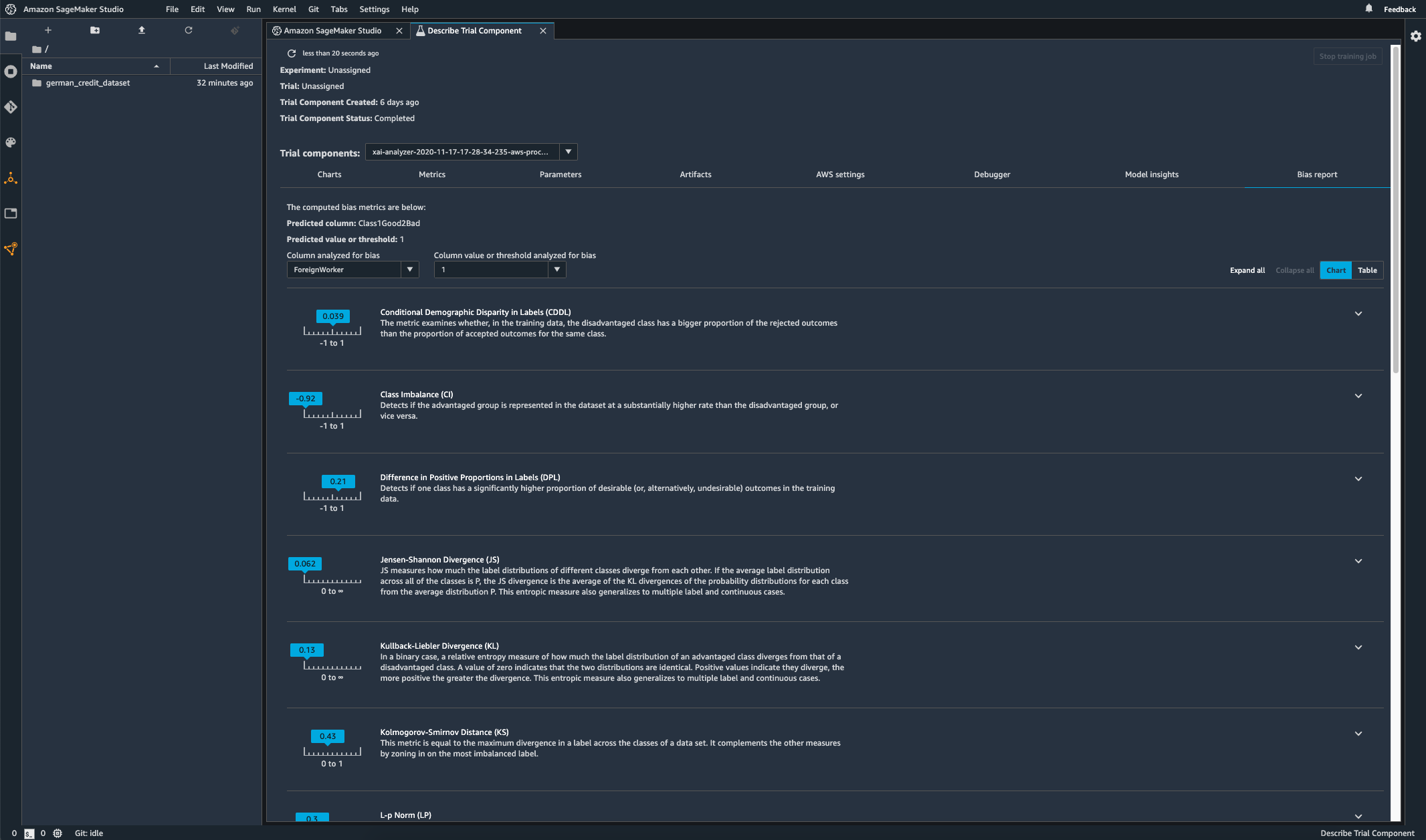
Contrôle de biais dans votre modèle entraîné
Après avoir entraîné votre modèle, vous pouvez exécuter une analyse de biais SageMaker Clarify à travers Amazon SageMaker Experiments pour vérifier que votre modèle ne présente pas de biais potentiels comme des prédictions qui produisent un résultat négatif plus fréquemment pour un groupe que pour un autre. Vous spécifiez les fonctionnalités d'entrée pour lesquelles vous souhaitez mesurer le biais dans les résultats du modèle, et SageMaker effectue une analyse et vous fournit un rapport visuel qui identifie les différents types de biais pour chaque fonctionnalité. La méthode open-source AWS Fair Bayesian Optimization peut aider à atténuer les biais en ajustant les hyper-paramètres d'un modèle.
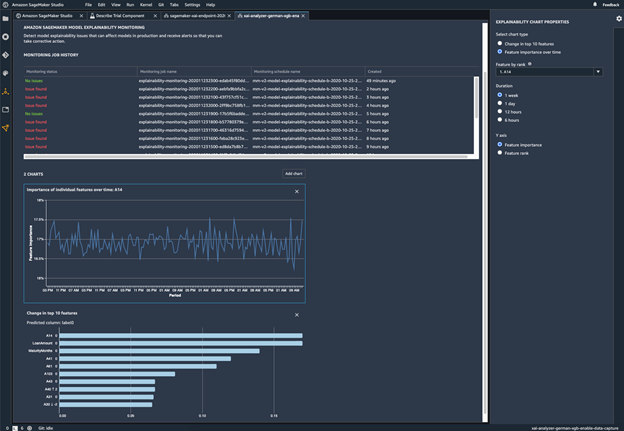
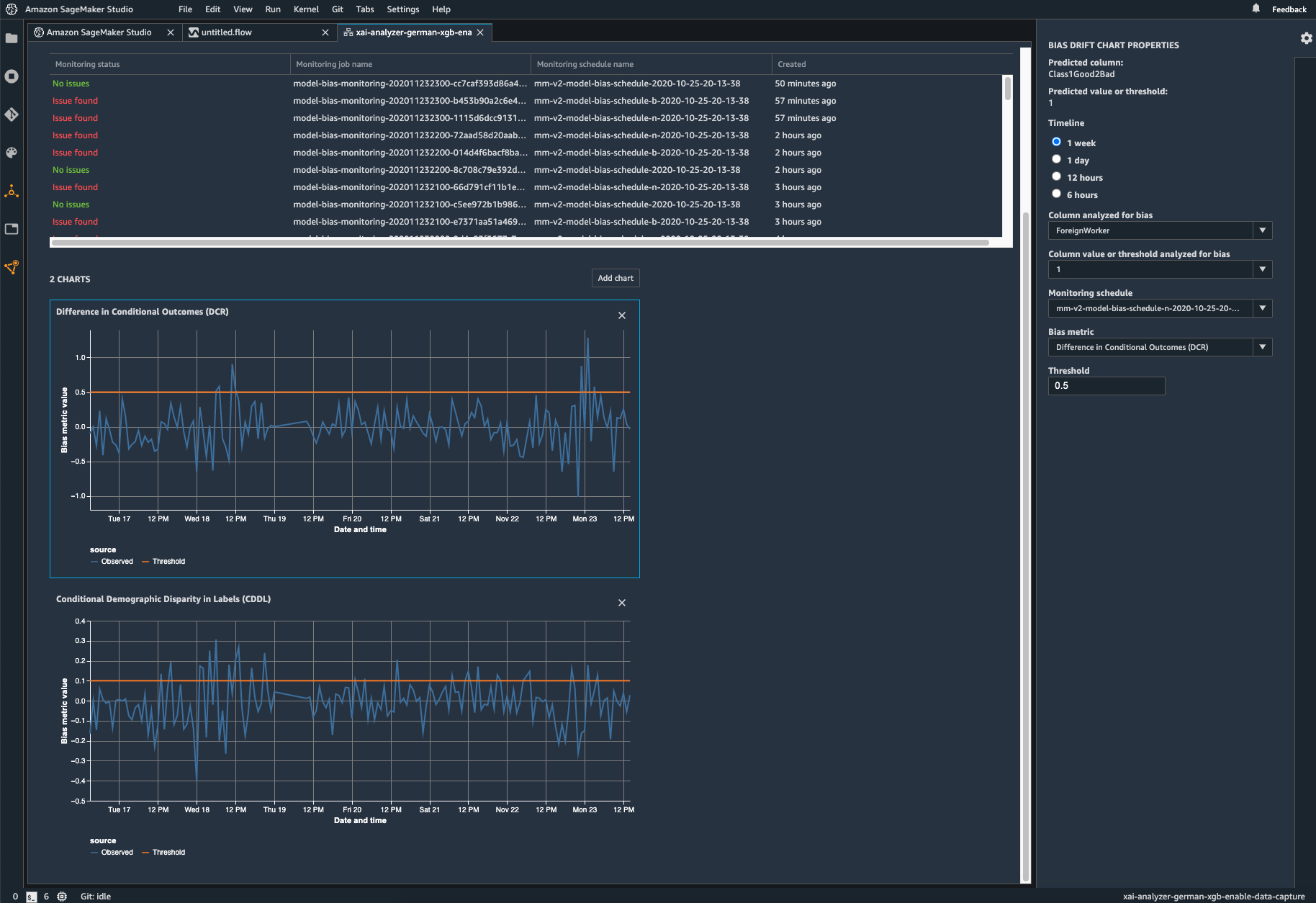
Surveiller votre modèle déployé pour détecter tout biais
Un biais peut être introduit ou exacerbé dans les modèles de ML déployés lorsque les données d'entraînement diffèrent des données réelles que le modèle voit pendant le déploiement. Par exemple, les résultats d'un modèle de prévision des prix des logements peuvent être biaisés si les taux hypothécaires utilisés pour former le modèle diffèrent des taux hypothécaires actuels. Les capacités de détection de biais de SageMaker Clarify sont intégrées à Amazon SageMaker Model Monitor de sorte que lorsque SageMaker détecte un biais au-delà d'un certain seuil, il génère automatiquement des mesures que vous pouvez visualiser dans Amazon SageMaker Studio et par le biais de mesures et d'alarmes Amazon CloudWatch.
Ressources
Nouveautés
- Date (de la plus récente à la plus ancienne)