Amazon Redshift
Cung cấp hiệu năng giá chưa từng có ở quy mô lớn với SQL cho hồ dữ liệu của bạnTại sao nên sử dụng Amazon Redshift?
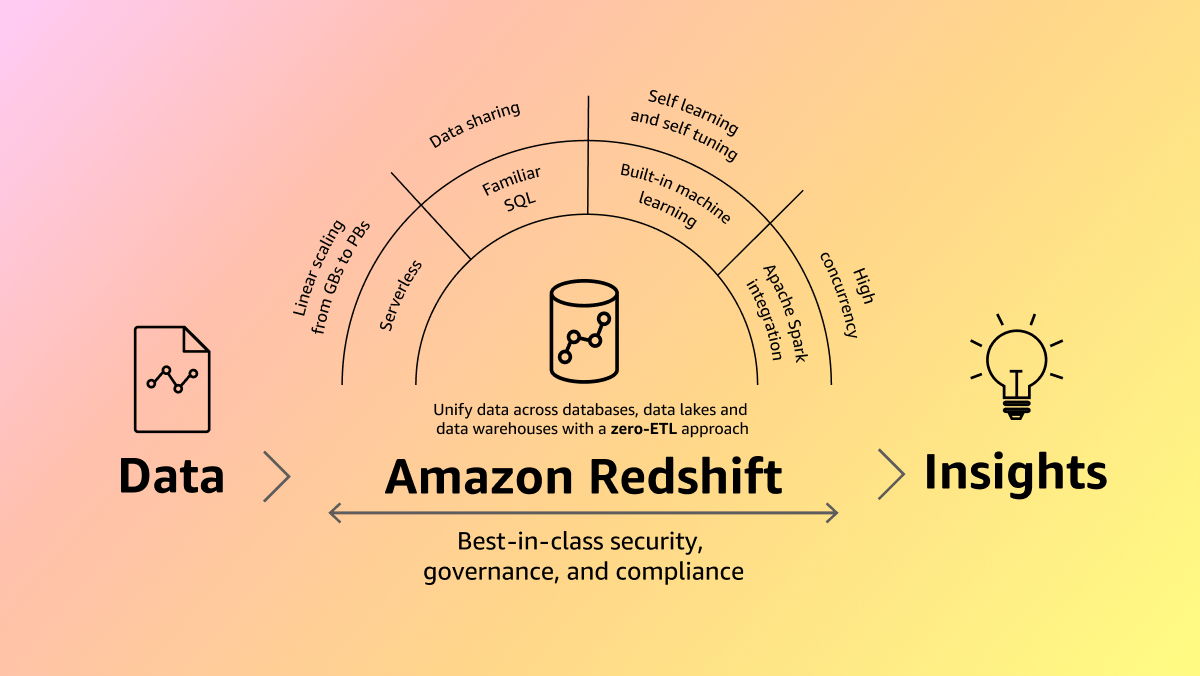
Hàng chục nghìn khách hàng sử dụng Amazon Redshift để phân tích dữ liệu hiện đại ở quy mô lớn, mang lại hiệu suất giá tốt hơn tới 3 lần và thông lượng tốt hơn tới 7 lần so với các kho dữ liệu đám mây khác. Amazon Redshift tích hợp liền mạch với Hồ dữ liệu Amazon SageMaker, cho phép bạn sử dụng khả năng phân tích SQL mạnh mẽ của giải pháp này cho dữ liệu hợp nhất của mình trên các kho dữ liệu Amazon Redshift và hồ dữ liệu Amazon Simple Storage Service (Amazon S3). Cho phép phân tích sát thời gian thực để tăng tốc tiến trình ra quyết định với tích hợp không ETL của Amazon Redshift, dịch vụ này kết nối dữ liệu từ các dịch vụ phát trực tuyến, cơ sở dữ liệu hoạt động và các ứng dụng doanh nghiệp của bên thứ ba mà không cần xây dựng quy trình dữ liệu phức tạp. Amazon Redshift phi máy chủ giúp bạn dễ dàng mở rộng quy mô phân tích, cho phép phân tích hàng petabyte dữ liệu không cần phải quản lý cơ sở hạ tầng. Nâng cao năng suất làm việc của đội ngũ với Amazon Q trong Amazon Redshift, giúp đơn giản hóa việc biên soạn SQL thông qua ngôn ngữ tự nhiên. Tối đa hóa giá trị dữ liệu của bạn bằng cách sử dụng Amazon Redshift làm cơ sở kiến thức có cấu trúc cho trợ lý AI tạo sinh trong Amazon Bedrock, mang lại kết quả chính xác và phù hợp hơn cho các ứng dụng.
Lợi ích
Cách thức hoạt động
Trường hợp sử dụng
Amazon Redshift phi máy chủ
Dễ dàng chạy và thay đổi quy mô phân tích chỉ trong vài giây mà không cần cung cấp và quản lý kho dữ liệu
Hôm nay, bạn đã tìm thấy nội dung mình cần chưa?
Chia sẻ với chúng tôi để chúng tôi có thể cải thiện chất lượng nội dung trên trang.