Cơ sở kiến thức về Amazon Bedrock
Với Cơ sở kiến thức của Amazon Bedrock, bạn có thể cung cấp cho các mô hình nền tảng và tác tử thông tin theo ngữ cảnh từ các nguồn dữ liệu riêng tư của công ty bạn nhằm đưa ra các phản hồi phù hợp hơn, chính xác hơn và được tùy chỉnh nhiều hơnKhả năng hỗ trợ được quản lý toàn phần cho quy trình làm việc RAG toàn diện
Để trang bị cho mô hình nền tảng (FM) thông tin độc quyền và cập nhật nhất, các tổ chức sử dụng kỹ thuật Tạo sinh tăng cường truy xuất (RAG), một kỹ thuật tìm nạp dữ liệu từ các nguồn dữ liệu của công ty và làm phong phú thêm câu lệnh để cung cấp các phản hồi phù hợp và chính xác hơn. Cơ sở kiến thức của Amazon Bedrock là một tính năng được quản lý toàn phần, tích hợp sẵn tính năng quản lý ngữ cảnh của phiên và phân bổ nguồn giúp bạn triển khai toàn bộ quy trình làm việc RAG từ tải nhập đến truy xuất và tăng cường câu lệnh mà không cần phải xây dựng các tích hợp tùy chỉnh cho các nguồn dữ liệu và quản lý luồng dữ liệu. Bạn cũng có thể đặt câu hỏi và tóm tắt dữ liệu từ một tài liệu duy nhất mà không cần thiết lập cơ sở dữ liệu véc-tơ. Nếu dữ liệu của bạn chứa các nguồn có cấu trúc, Cơ sở kiến thức của Amazon Bedrock cung cấp ngôn ngữ tự nhiên được quản lý tích hợp sẵn sang ngôn ngữ truy vấn có cấu trúc để tạo lệnh truy vấn nhằm truy xuất dữ liệu mà không cần phải di chuyển chúng sang kho lưu trữ khác.

Kết nối bảo mật các FM và tác tử với các nguồn dữ liệu
Nếu bạn có nguồn dữ liệu phi cấu trúc, Cơ sở kiến thức của Amazon Bedrock sẽ tự động tìm nạp dữ liệu từ các nguồn như Amazon Simple Storage Service (Amazon S3), Confluence (bản xem trước), Salesforce (bản xem trước), SharePoint (bản xem trước) hoặc Web Crawler (xem trước). Ngoài ra, bạn cũng nhận được tính năng tải nhập tài liệu theo lập trình để cho phép khách hàng tải nhập dữ liệu truyền liên tục hoặc dữ liệu từ các nguồn không được hỗ trợ. Sau khi nội dung đã được tải nhập, Cơ sở kiến thức của Amazon Bedrock chia nội dung thành các khối văn bản, chuyển đổi từ văn bản thành phần nhúng và lưu trữ chúng trong cơ sở dữ liệu véc-tơ của bạn. Bạn có thể chọn từ nhiều kho lưu trữ véc-tơ được hỗ trợ, bao gồm Amazon Aurora, Amazon OpenSearch phi máy chủ, Phân tích Amazon Neptune, MongoDB, Pinecone và Đám mây Redis Enterprise. Bạn cũng có thể chọn kết nối với chỉ mục tìm kiếm kết hợp Amazon Kendra cho hoạt động truy xuất được quản lý
Sử dụng Cơ sở kiến thức của Amazon Bedrock, bạn cũng có thể kết nối với kho dữ liệu có cấu trúc của mình để tạo phản hồi có căn cứ. Điều này có thể đặc biệt hữu ích khi bạn có tài liệu nguồn như chi tiết giao dịch được lưu trữ trong kho dữ liệu và hồ dữ liệu. Cơ sở kiến thức của Amazon Bedrock sử dụng Ngôn ngữ tự nhiên sang SQL để chuyển đổi các truy vấn thành các lệnh SQL và thực thi các lệnh để truy xuất dữ liệu mà không cần phải di chuyển chúng từ nguồn dữ liệu nguồn của bạn.

Tùy chỉnh Cơ sở kiến thức của Amazon Bedrock để cung cấp phản hồi chính xác trong thời gian hoạt động
Sử dụng Cơ sở kiến thức của Amazon Bedrock làm giải pháp RAG được quản lý toàn phần, bạn có thể linh hoạt tùy chỉnh và cải thiện độ chính xác truy xuất. Đối với các nguồn dữ liệu phi cấu trúc chứa dữ liệu đa phương thức như hình ảnh và tài liệu nhiều hình ảnh với bố cục phức tạp (ví dụ: tài liệu chứa bảng, hình vẽ, biểu đồ và sơ đồ), bạn có thể cấu hình Cơ sở kiến thức của Bedrock để phân tích cú pháp, phân tích và trích xuất thông tin chuyên sâu có ý nghĩa. Bạn có thể chọn Tự động hóa dữ liệu của Bedrock hoặc mô hình nền tảng làm trình phân tích cú pháp. Điều này cho phép xử lý liền mạch dữ liệu đa phương thức phức tạp, để bạn có thể xây dựng các ứng dụng AI tạo sinh có độ chính xác cao.
Cơ sở kiến thức của Amazon Bedrock cung cấp nhiều tùy chọn phân đoạn dữ liệu nâng cao, bao gồm phân đoạn theo ngữ nghĩa, phân cấp và kích thước cố định. Để có toàn quyền kiểm soát, bạn có thể viết mã phân đoạn của riêng mình dưới dạng hàm Lambda, thậm chí sử dụng các thành phần sẵn có từ các khung như LangChain và LlamaIndex. Nếu bạn chọn Phân tích Amazon Neptune làm kho lưu trữ véc-tơ, Cơ sở kiến thức của Amazon Bedrock sẽ tự động tạo các phần nhúng cũng như biểu đồ liên kết nội dung liên quan giữa các nguồn dữ liệu của bạn. Cơ sở kiến thức của Bedrock tận dụng các mối quan hệ nội dung này với GraphRAG để cải thiện độ chính xác của việc truy xuất, cho phép các phản hồi toàn diện, phù hợp và có thể lý giải được cho người dùng cuối.

Truy xuất dữ liệu và tăng cường câu lệnh
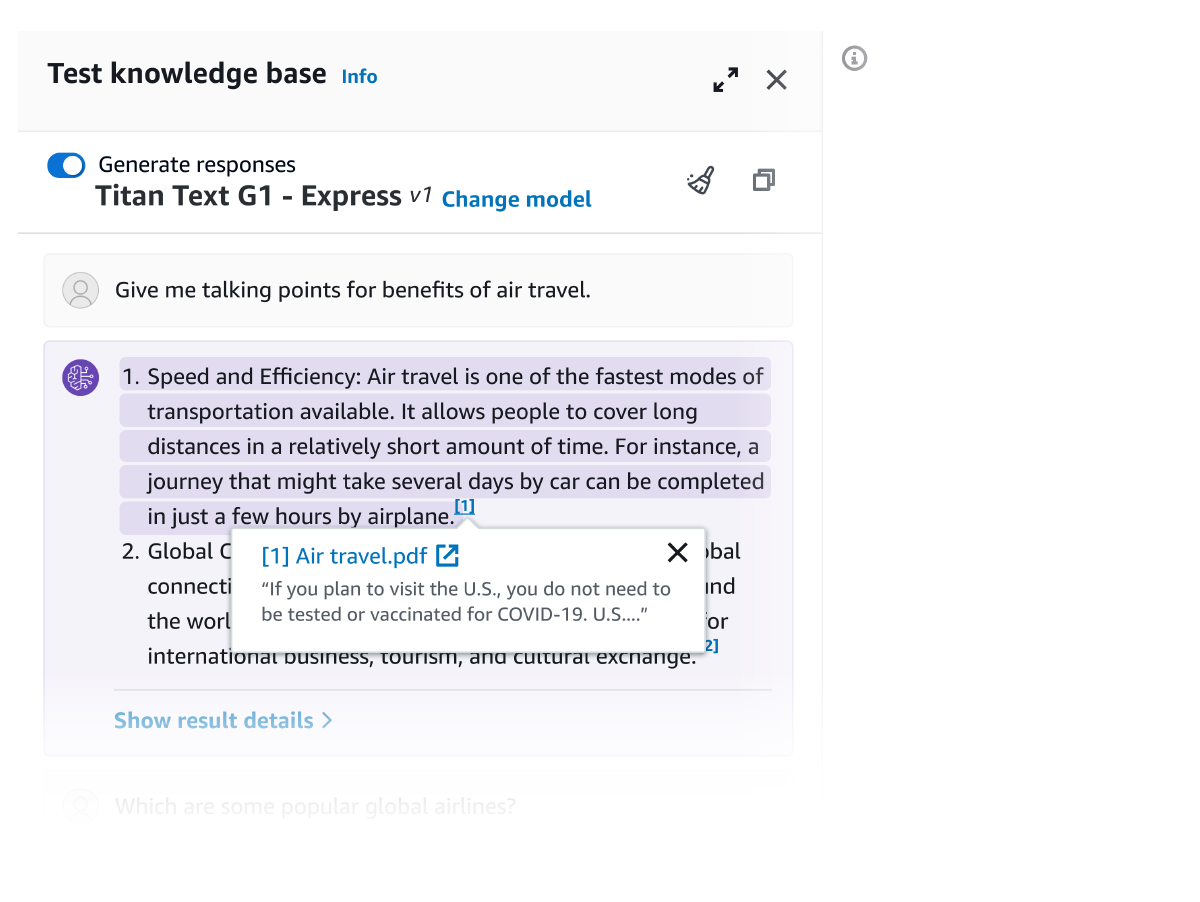
Sử dụng API Truy xuất, bạn có thể tìm nạp kết quả có liên quan cho truy vấn của người dùng từ cơ sở kiến thức, bao gồm các yếu tố trực quan như hình ảnh, sơ đồ, biểu đồ và bảng hoặc dữ liệu có cấu trúc từ cơ sở dữ liệu khi có thể. API RetrieveAndGenerate tiến một bước xa hơn bằng cách trực tiếp sử dụng kết quả được truy xuất để tăng cường câu lệnh FM và trả về phản hồi. Bạn cũng có thể thêm Cơ sở kiến thức của Amazon Bedrock vào Tác tử của Amazon Bedrock để cung cấp thông tin theo ngữ cảnh cho các nhân viên. Bạn cũng có thể chọn cung cấp các bộ lọc hoặc sử dụng FM để tạo các bộ lọc ngầm để giới hạn kết quả trả về chỉ trong nội dung có liên quan. Cơ sở kiến thức của Amazon Bedrock cung cấp các mô hình xếp hạng lại để cải thiện mức độ liên quan của các đoạn tài liệu được truy xuất.

Cung cấp phân bổ nguồn
Tất cả thông tin được truy xuất từ Cơ sở kiến thức của Amazon Bedrock được cung cấp với các trích dẫn (cũng bao gồm hình ảnh) để cải thiện tính minh bạch và giảm thiểu ảo giác.
Hôm nay, bạn đã tìm thấy nội dung mình cần chưa?
Chia sẻ với chúng tôi để chúng tôi có thể cải thiện chất lượng nội dung trên trang.