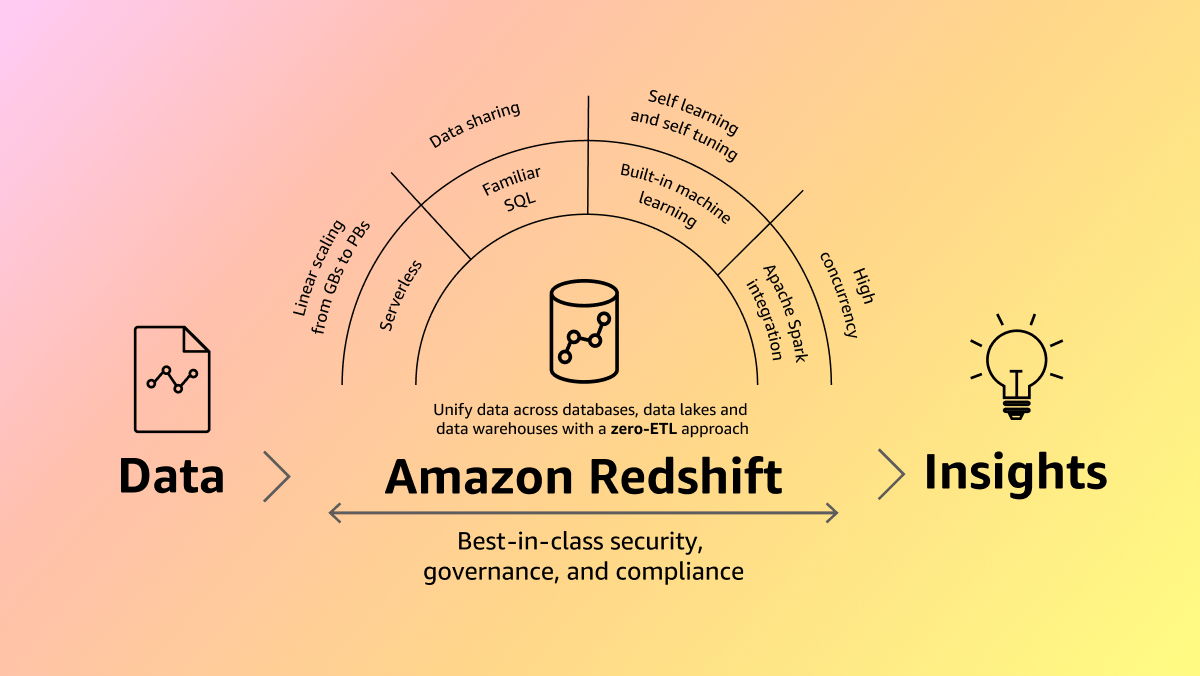
Amazon Redshift
ส่งมอบประสิทธิภาพต่อราคาที่ยิ่งใหญ่อย่างที่ไม่มีใครเทียบได้ด้วย SQL สำหรับ Data Lakehouse ของคุณทำไมต้อง Amazon Redshift
ลูกค้าหลายหมื่นคนใช้ Amazon Redshift สำหรับการวิเคราะห์ข้อมูลที่ทันสมัยในทุกระดับ ซึ่งส่งมอบประสิทธิภาพด้านราคาที่ดีขึ้นถึง 3 เท่าและมีอัตราการโอนถ่ายข้อมูลที่ดีกว่าคลังข้อมูลบนระบบคลาวด์อื่น ๆ ถึง 7 เท่า Amazon Redshift ผสานรวมเข้ากับ Amazon SageMaker Lakehouse ได้อย่างราบรื่น ซึ่งช่วยให้คุณสามารถใช้ความสามารถในการวิเคราะห์ SQL ที่มีประสิทธิภาพกับข้อมูลแบบรวมในคลังข้อมูลของ Amazon Redshift และ Data Lake ของ Amazon Simple Storage Service (Amazon S3) เปิดใช้งานการวิเคราะห์แบบแทบจะเรียลไทม์เพื่อเร่งการตัดสินใจด้วยการบูรณาการ ETL แบบไร้รอยต่อของ Amazon Redshift ซึ่งเชื่อมต่อข้อมูลจากบริการสตรีมมิ่ง ฐานข้อมูลการดำเนินงาน และแอปพลิเคชันองค์กรจากภายนอกโดยที่ไม่ต้องสร้างไปป์ไลน์ข้อมูลที่ซับซ้อน Amazon Redshift แบบไม่ต้องใช้เซิร์ฟเวอร์ทำให้การปรับขนาดการวิเคราะห์เป็นไปอย่างง่ายดาย ซึ่งช่วยให้คุณสามารถวิเคราะห์ข้อมูลระดับเพตะไบต์ได้โดยไม่ต้องมีภาระในการจัดการโครงสร้างพื้นฐาน เพิ่มประสิทธิภาพการทำงานของทีมด้วย Amazon Q ใน Amazon Redshift ซึ่งช่วยลดความยุ่งยากในการเขียน SQL ด้วยภาษาธรรมชาติ เพิ่มมูลค่าของข้อมูลให้สูงสุดโดยใช้ Amazon Redshift เป็นฐานความรู้ที่มีโครงสร้างสำหรับผู้ช่วยที่เป็น AI ช่วยสร้างใน Amazon Bedrock ซึ่งทำให้ได้ผลลัพธ์ที่เกี่ยวข้องและถูกต้องแม่นยำยิ่งขึ้นสำหรับแอปพลิเคชันของคุณ
ประโยชน์
วิธีทำงาน
กรณีใช้งาน
Amazon Redshift แบบไม่ต้องใช้เซิร์ฟเวอร์
เรียกใช้และปรับขนาดการวิเคราะห์ได้อย่างง่ายดายในไม่กี่วินาทีโดยไม่ต้องจัดเตรียมและจัดการคลังข้อมูล
วันนี้คุณพบสิ่งที่กำลังมองหาแล้วหรือยัง
การแจ้งให้เราทราบจะช่วยให้เราปรับปรุงคุณภาพของเนื้อหาในหน้าเว็บได้