Criar um modelo de machine learning automaticamente
com o Amazon SageMaker Autopilot
O Amazon SageMaker é um serviço totalmente gerenciado que fornece a todos os desenvolvedores e cientistas de dados a capacidade de criar, treinar e implantar modelos de machine learning (ML) rapidamente.
Neste tutorial, você cria modelos de machine learning automaticamente sem escrever uma linha de código. Você usa o Amazon SageMaker Autopilot, um recurso AutoML que cria automaticamente os melhores modelos de machine learning de classificação e regressão, permitindo total controle e visibilidade.
Neste tutorial, você aprenderá a:
- Criar uma conta da AWS
- Configurar o Amazon SageMaker Studio para acessar o Amazon SageMaker Autopilot
- Fazer download de um conjunto de dados público usando o Amazon SageMaker Studio
- Criar um experimento de treinamento com o Amazon SageMaker Autopilot
- Explorar as diferentes etapas do experimento de treinamento
- Identificar e implantar o modelo com melhor performance do experimento de treinamento
- Prever com seu modelo implantado
Neste tutorial, você assumirá a função de um desenvolvedor que trabalha em um banco. Solicitaram que você desenvolva um modelo de machine learning para prever se um cliente se inscreverá para um certificado de depósito (CD). O modelo será treinado no conjunto de dados de marketing que contém informações sobre a demografia do cliente, respostas a eventos de marketing e fatores externos.
| Sobre este tutorial | |
|---|---|
| Duração | 10 minutos |
| Custo | Menos de 10 USD |
| Caso de uso | Machine Learning |
| Produtos | Amazon SageMaker |
| Público | Desenvolvedor |
| Nível | Iniciante |
| Data da última atualização | 12 de maio de 2020 |
Etapa 1. Criar uma conta da AWS
O custo deste workshop é inferior a 10 USD. Para obter mais informações, consulte a definição de preço do Amazon SageMaker Studio.
Você já tem uma conta? Faça login
Etapa 2. Configurar o Amazon SageMaker Studio
Conclua as etapas a seguir para integrar o Amazon SageMaker Studio para acessar o Amazon SageMaker Autopilot.
Observação: Para obter mais informações, consulte Get Started with Amazon SageMaker Studio na documentação do Amazon SageMaker.
a. Faça login no console do Amazon SageMaker.
Observação: No canto superior direito, selecione uma Região da AWS em que o Amazon SageMaker Studio esteja disponível. Para obter uma lista de Regiões, consulte Onboard to Amazon SageMaker Studio.


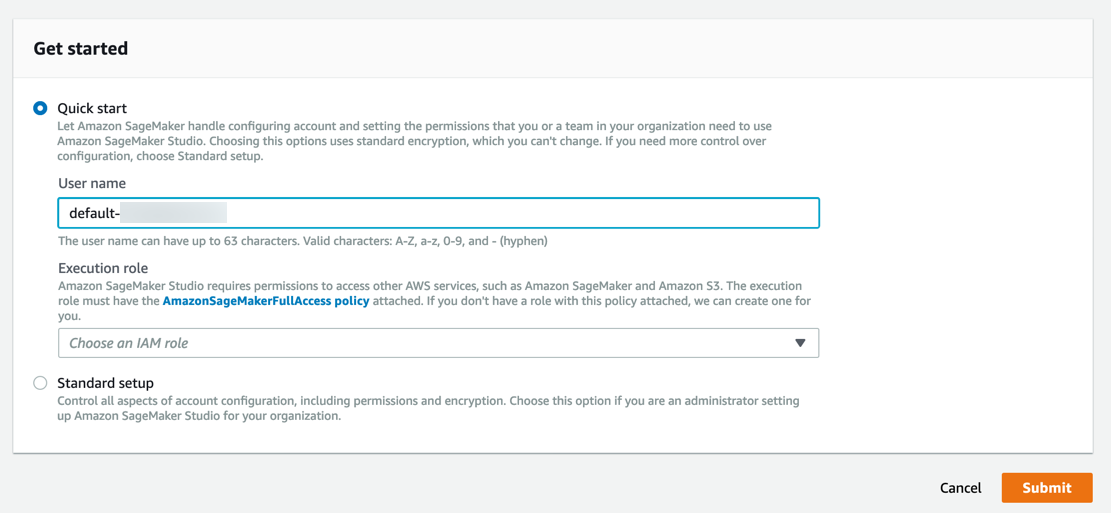
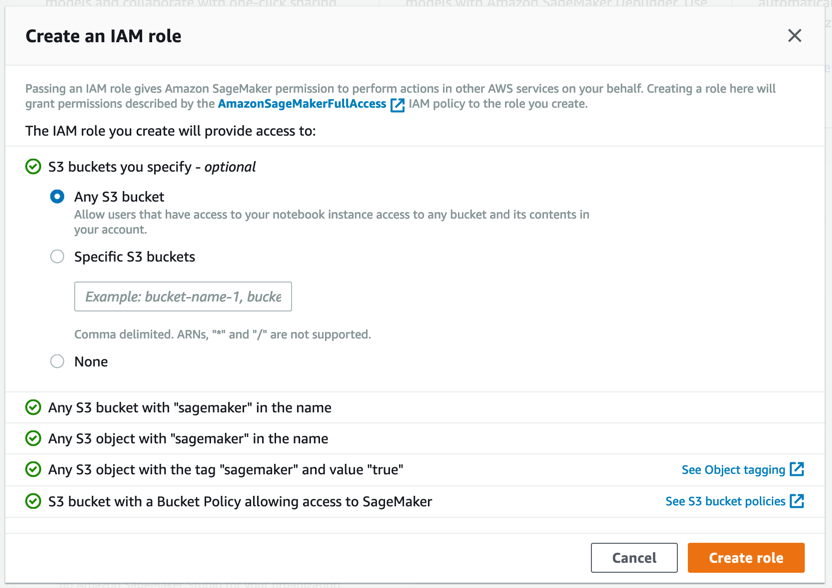
O Amazon SageMaker cria uma função com as permissões necessárias e a atribui à sua instância.
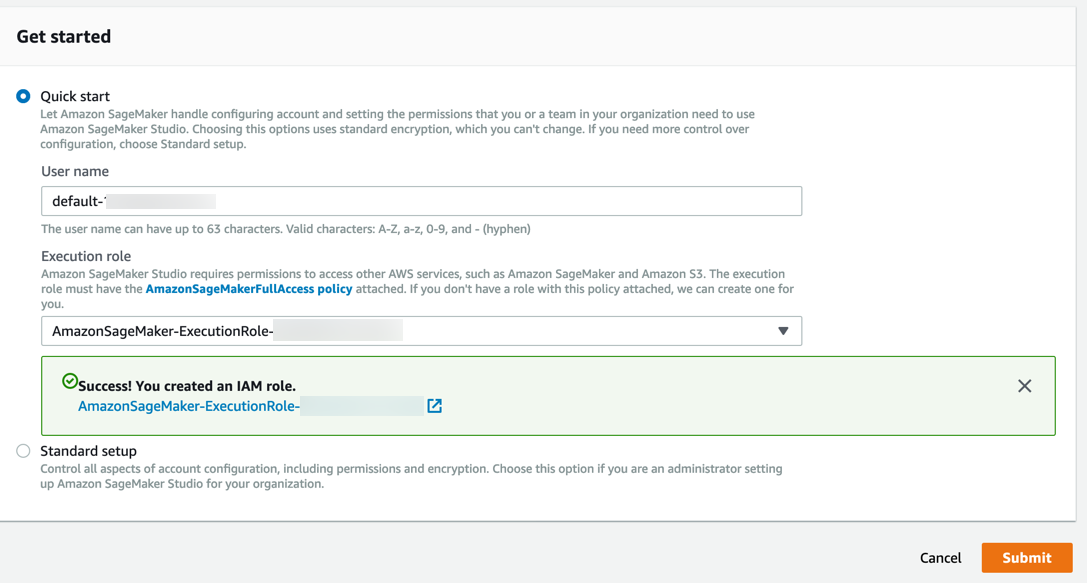
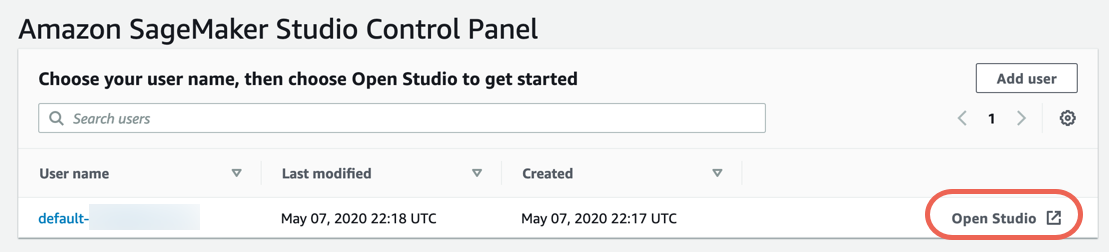
Etapa 3. Fazer download do conjunto de dados
Conclua as etapas a seguir para fazer download e explorar o conjunto de dados.
Observação: Para obter mais informações, consulte Amazon SageMaker Studio tour na documentação do Amazon SageMaker.
%%sh
apt-get install -y unzip
wget https://sagemaker-sample-data-us-west-2.s3-us-west-2.amazonaws.com/autopilot/direct_marketing/bank-additional.zip
unzip -o bank-additional.zip
d. Copie e cole o seguinte código em uma nova célula de código e selecione Run.
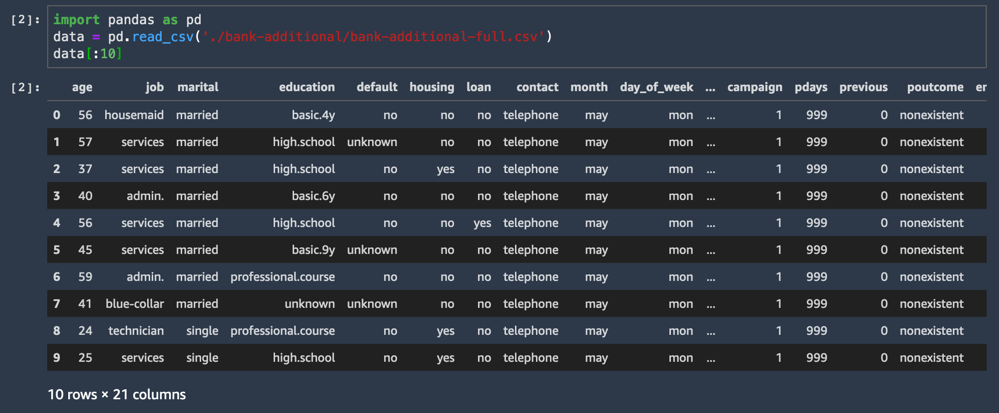
O conjunto de dados CSV é carregado e exibe as dez primeiras linhas.
import pandas as pd
data = pd.read_csv('./bank-additional/bank-additional-full.csv')
data[:10]Uma das colunas do conjunto de dados é chamada de y e representa o rótulo de cada amostra: esse cliente aceitou a oferta ou não?
Essa etapa é onde os cientistas de dados começam a explorar os dados, criando novos recursos e assim por diante. Com o Amazon SageMaker Autopilot, você não precisa executar nenhuma dessas etapas extras. Basta fazer upload de dados tabulares em um arquivo com valores separados por vírgula (por exemplo, de uma planilha ou banco de dados), escolher a coluna de destino a ser prevista e o Autopilot criará um modelo preditivo para você.
d. Copie e cole o seguinte código em uma nova célula de código e selecione Run.
Essa etapa faz upload de um conjunto de dados CSV para um bucket do Amazon S3. Você não precisa criar um bucket do Amazon S3. O Amazon SageMaker cria automaticamente um bucket padrão em sua conta quando você faz upload dos dados.
import sagemaker
prefix = 'sagemaker/tutorial-autopilot/input'
sess = sagemaker.Session()
uri = sess.upload_data(path="./bank-additional/bank-additional-full.csv", key_prefix=prefix)
print(uri)
Está pronto! A saída de código exibe o URI do bucket do S3 como no exemplo a seguir:
s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/input/bank-additional-full.csvAcompanhe o URI do S3 impresso em seu próprio bloco de anotações. Você precisará dele na próxima etapa.

Etapa 4. Criar um experimento do SageMaker Autopilot
Agora que você fez download e preparou seu conjunto de dados no Amazon S3, pode criar um experimento do Amazon SageMaker Autopilot. Um experimento é uma coleção de trabalhos de processamento e treinamento relacionadas ao mesmo projeto de machine learning.
Siga as etapas abaixo para criar um novo experimento.
Observação: Para obter mais informações, consulte Create an Amazon SageMaker Autopilot Experiment in SageMaker Studio na documentação do Amazon SageMaker.
a. No painel de navegação esquerdo do Amazon SageMaker Studio, escolha Experiments (ícone simbolizado por um balão) e escolha Create Experiment.
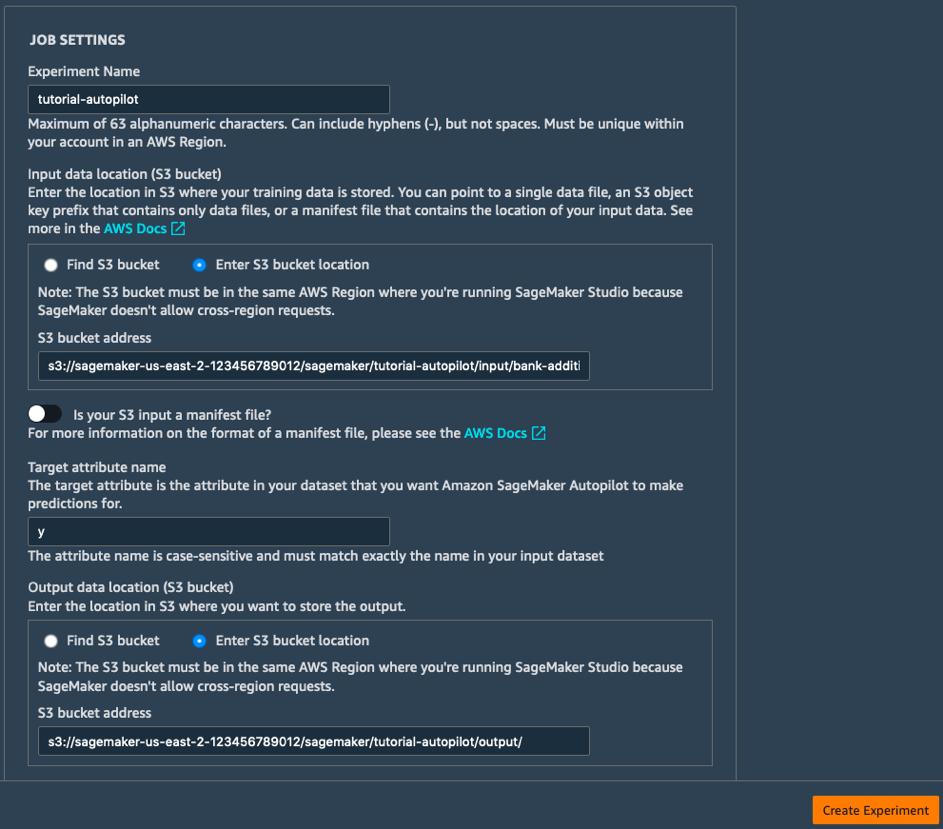
b. Preencha os campos Job Settings da seguinte maneira:
- Experiment Name: tutorial-autopilot
- S3 location of input data: URI do S3 que você imprimiu acima
(por exemplo, s3://sagemaker-us-east-2-123456789012/sagemaker/tutorial-autopilot/input/bank-additional-full.csv) - Target attribute name: y
- S3 location for output data: s3://sagemaker-us-east-2-[NÚMERO-CONTA]/sagemaker/tutorial-autopilot/output
(lembre-se de substituir [NÚMERO-CONTA] pelo seu próprio número de conta)
c. Deixe todas as outras configurações como padrão e escolha Create Experiment.
Êxito! Isso inicia o experimento do Amazon SageMaker Autopilot. O processo gerará um modelo e estatísticas que você pode visualizar em tempo real enquanto o experimento está em execução. Após a conclusão do experimento, você pode visualizar as avaliações, classificar por métrica objetiva e clicar com o botão direito do mouse para implantar o modelo para uso em outros ambientes.
Etapa 5. Explorar os estágios do experimento do SageMaker Autopilot
Enquanto seu experimento está em andamento, você pode aprender e explorar os diferentes estágios do experimento do SageMaker Autopilot.
Esta seção fornece mais detalhes sobre os estágios do experimento do SageMaker Autopilot:
- Análise de dados
- Engenharia de recursos
- Ajuste de modelos
Observação: Para obter informações, consulte SageMaker Autopilot Notebook Output.
Análise de dados
O estágio de Análise de dados identifica o tipo de problema a ser resolvido (regressão linear, classificação binária, classificação multiclasse). Em seguida, ele cria dez pipelines candidatos. Um pipeline combina uma etapa de pré-processamento de dados (tratamento de valores ausentes, novos recursos de engenharia etc.) e uma etapa de treinamento do modelo usando um algoritmo de ML que corresponde ao tipo de problema. Quando essa etapa é concluída, o trabalho passa para a engenharia de recursos.
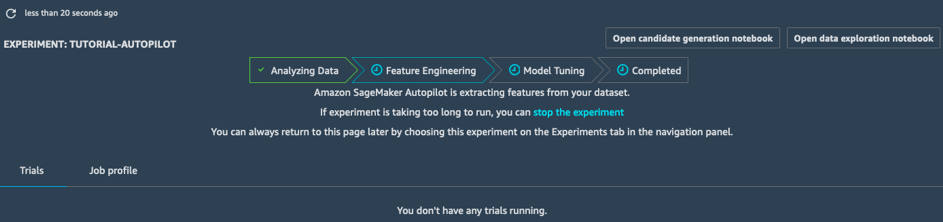
Engenharia de recursos
No estágio de Engenharia de recursos, o experimento cria conjuntos de dados de treinamento e validação para cada pipeline candidato, armazenando todos os artefatos no seu bucket do S3. Enquanto estiver no estágio de Engenharia de recursos, você poderá abrir e visualizar dois blocos de notas gerados automaticamente:
- O bloco de notas de exploração de dados contém informações e estatísticas sobre o conjunto de dados.
- O bloco de notas de geração de candidatos contém a definição dos dez pipelines. Na verdade, este é um bloco de notas executável: você pode reproduzir exatamente o que o trabalho do AutoPilot faz, entender como os diferentes modelos são criados e até mesmo ajustá-los, se assim desejar.
Com esses dois blocos de anotações, você pode entender em detalhes como os dados são pré-processados e como os modelos são criados e otimizados. Essa transparência é um recurso importante do Amazon SageMaker Autopilot.
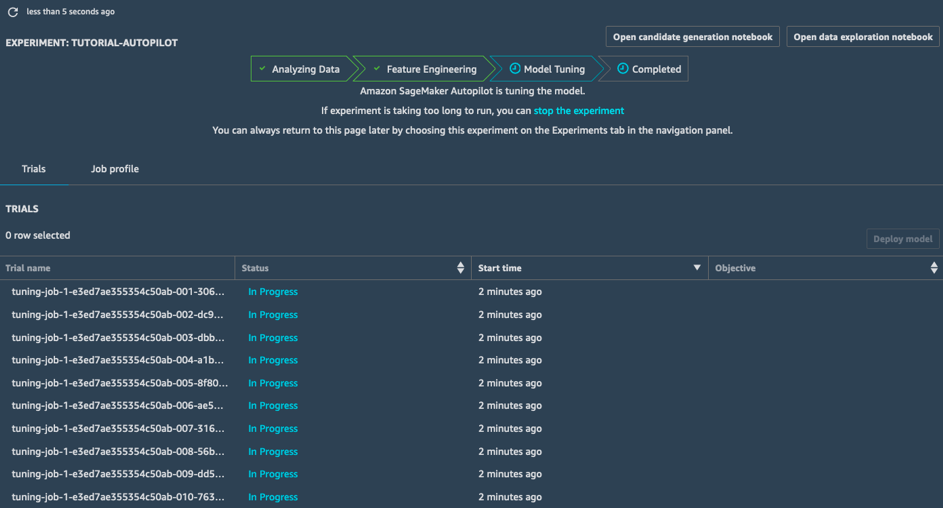
Ajuste de modelos
No estágio de Ajuste de modelos, para cada pipeline candidato e seu conjunto de dados pré-processado, o SageMaker Autopilot inicia um trabalho de otimização de hiperparâmetros; os trabalhos de treinamento associados exploram uma ampla gama de valores de hiperparâmetros e são convergidos rapidamente para modelos de alta performance.
Quando esse estágio estiver concluído, o trabalho do SageMaker Autopilot estará concluído. Você pode visualizar e explorar todos os trabalhos no SageMaker Studio.
Etapa 6. Implantar o melhor modelo
Agora que seu experimento foi concluído, você pode escolher o melhor modelo de ajuste e implantar o modelo em um endpoint gerenciado pelo Amazon SageMaker.
Siga estas etapas para escolher o melhor trabalho de ajuste e implantar o modelo.
Observação: Para obter mais informações, consulte Escolher e implantar o melhor modelo.
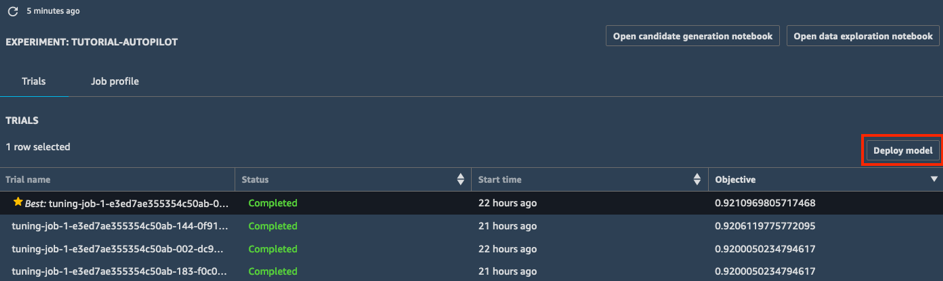
a. Na lista Trials do seu experimento, escolha o símbolo de ordenação ao lado de Objective para classificar os trabalhos de ajuste em ordem decrescente. O melhor trabalho de ajuste é destacado com uma estrela.
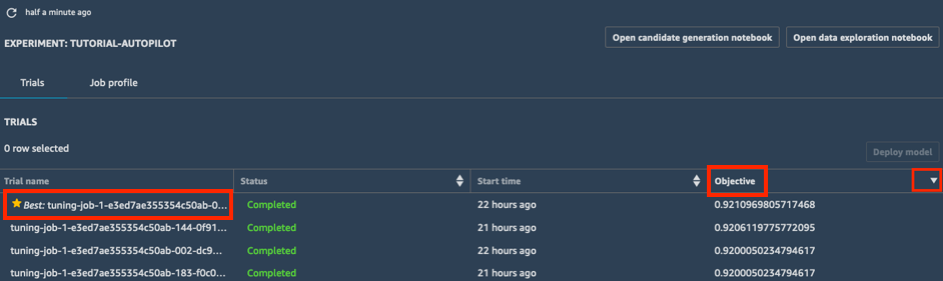
b. Selecione o melhor trabalho de ajuste (indicado por uma estrela) e escolha Deploy model.
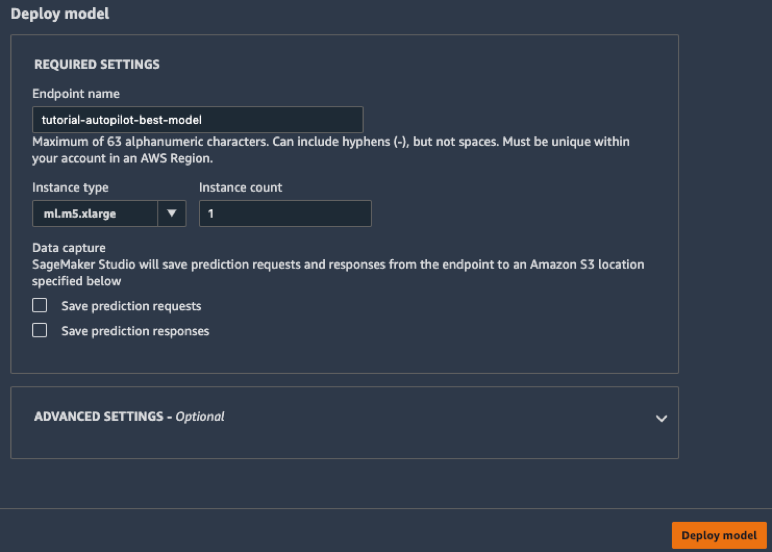
c. Na caixa Deploy model, dê um nome para seu endpoint (por exemplo tutorial-autopilot-best-model) e deixe todas as configurações como padrão. Escolha Deploy model.
Seu modelo é implantado em um endpoint HTTPS gerenciado pelo Amazon SageMaker.
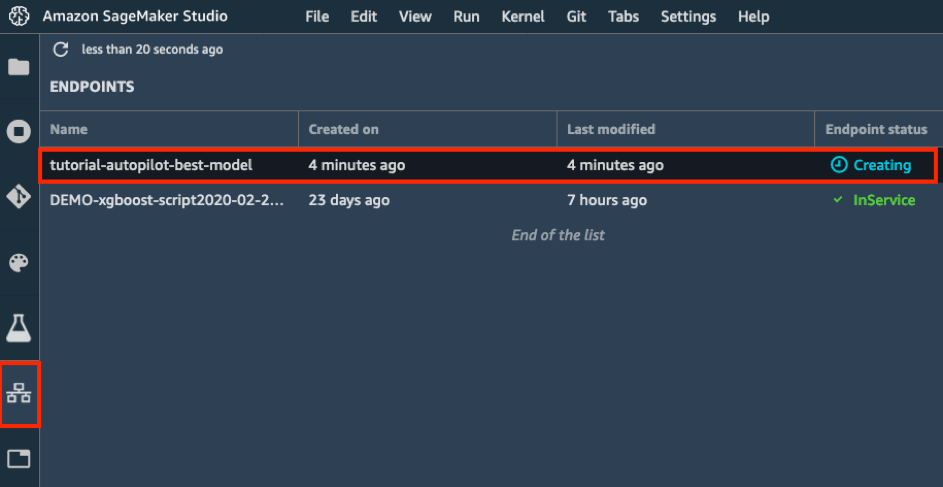
d. Na barra de ferramentas esquerda, escolha o ícone Endpoints. Você pode ver seu modelo sendo criado, o que levará alguns minutos. Quando o status de endpoint é InService, você pode enviar dados e receber previsões.
Etapa 7. Prever com seu modelo
Agora que o modelo foi implantado, é possível prever as primeiras 2.000 amostras do conjunto de dados. Para esse fim, você usa a API invoke_endpoint no SDK boto3. No processo, você calcula métricas importantes de machine learning: fidelidade, precisão, recuperação e pontuação F1.
Siga estas etapas para prever com seu modelo.
Observação: Para obter mais informações, consulte Manage Machine Learning with Amazon SageMaker Experiments.
No seu bloco de anotações do Jupyter, copie e cole o seguinte código e escolha Run.
import boto3, sys
ep_name = 'tutorial-autopilot-best-model'
sm_rt = boto3.Session().client('runtime.sagemaker')
tn=tp=fn=fp=count=0
with open('bank-additional/bank-additional-full.csv') as f:
lines = f.readlines()
for l in lines[1:2000]: # Skip header
l = l.split(',') # Split CSV line into features
label = l[-1] # Store 'yes'/'no' label
l = l[:-1] # Remove label
l = ','.join(l) # Rebuild CSV line without label
response = sm_rt.invoke_endpoint(EndpointName=ep_name,
ContentType='text/csv',
Accept='text/csv', Body=l)
response = response['Body'].read().decode("utf-8")
#print ("label %s response %s" %(label,response))
if 'yes' in label:
# Sample is positive
if 'yes' in response:
# True positive
tp=tp+1
else:
# False negative
fn=fn+1
else:
# Sample is negative
if 'no' in response:
# True negative
tn=tn+1
else:
# False positive
fp=fp+1
count = count+1
if (count % 100 == 0):
sys.stdout.write(str(count)+' ')
print ("Done")
accuracy = (tp+tn)/(tp+tn+fp+fn)
precision = tp/(tp+fp)
recall = tn/(tn+fn)
f1 = (2*precision*recall)/(precision+recall)
print ("%.4f %.4f %.4f %.4f" % (accuracy, precision, recall, f1))
A seguinte saída será exibida.
100 200 300 400 500 600 700 800 900 1000 1100 1200 1300 1400 1500 1600 1700 1800 1900 Done
0.9830 0.6538 0.9873 0.7867
Esta saída é um indicador de progresso que mostra o número de amostras que foram previstas.
Etapa 8. Limpar
Nesta etapa, você encerra os recursos que você usou neste laboratório.
Importante: é recomendável encerrar os recursos que não estão em uso, pois isso reduz custos. Se os recursos não forem encerrados, sua conta será cobrada.
Excluir seu endpoint: no seu bloco de anotações do Jupyter, copie e cole o seguinte código e escolha Run.
sess.delete_endpoint(endpoint_name=ep_name)Se você desejar limpar todos os artefatos de treinamento (modelos, conjuntos de dados pré-processados etc.), copie e cole o seguinte código em sua célula de código e escolha Run.
Observação: Lembre-se de substituir NÚMERO_CONTA pelo seu número de conta.
%%sh
aws s3 rm --recursive s3://sagemaker-us-east-2-ACCOUNT_NUMBER/sagemaker/tutorial-autopilot/Parabéns
Você criou um modelo de machine learning com a melhor precisão automaticamente com o Amazon SageMaker Autopilot.
Próximas etapas recomendadas
Explorar exemplos de blocos de anotações de ML
Fazer um tour do Amazon SageMaker Studio
Saiba mais sobre o Amazon SageMaker Autopilot
Caso deseje saber mais, leia o artigo de blog ou consulte a série de vídeos do Autopilot.