Amazon SageMaker Clarify란 무엇인가요?
SageMaker Clarify의 이점
기초 모델 평가
평가 마법사 및 보고서
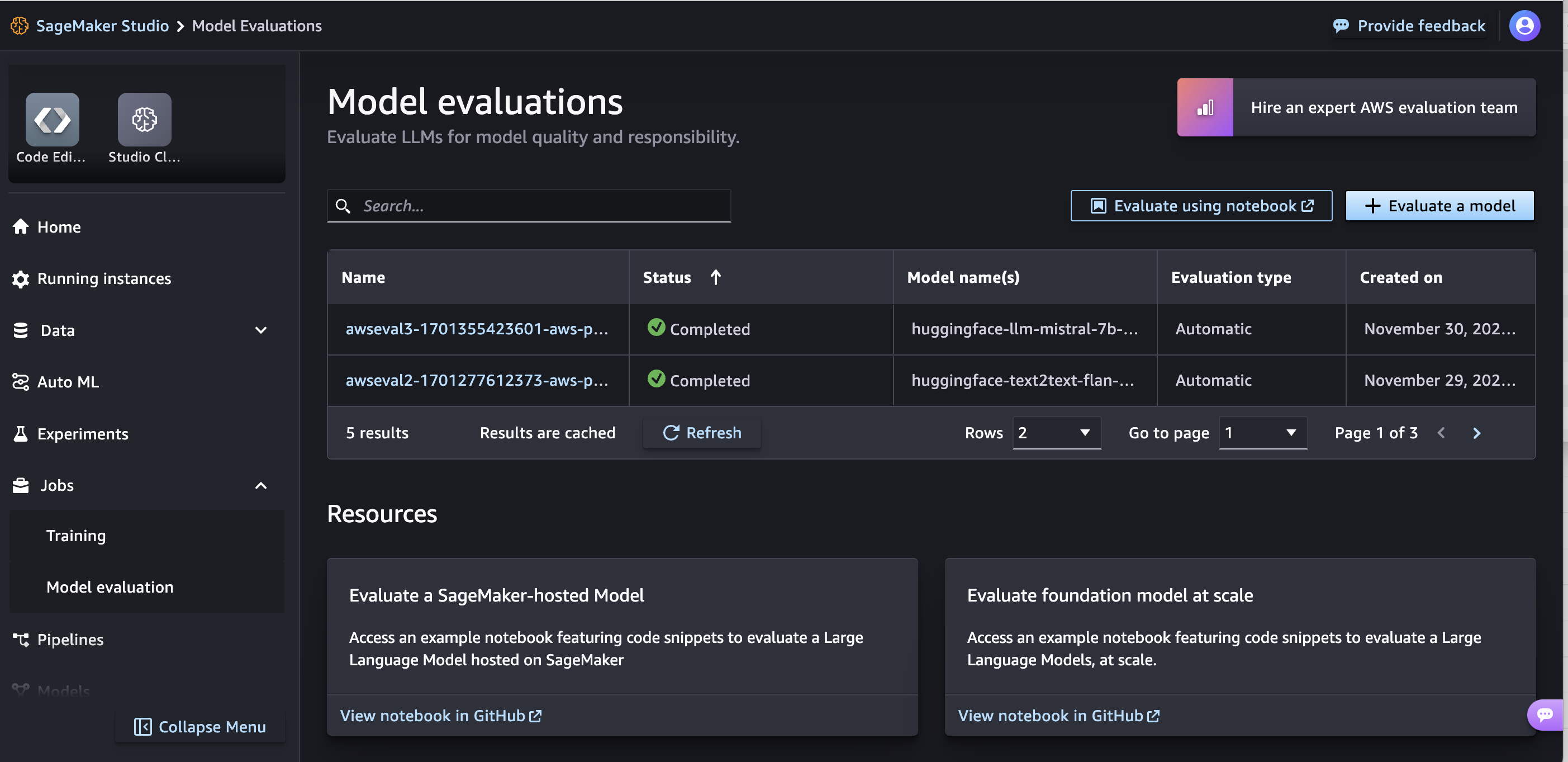
사용자 지정
사람 기반 평가
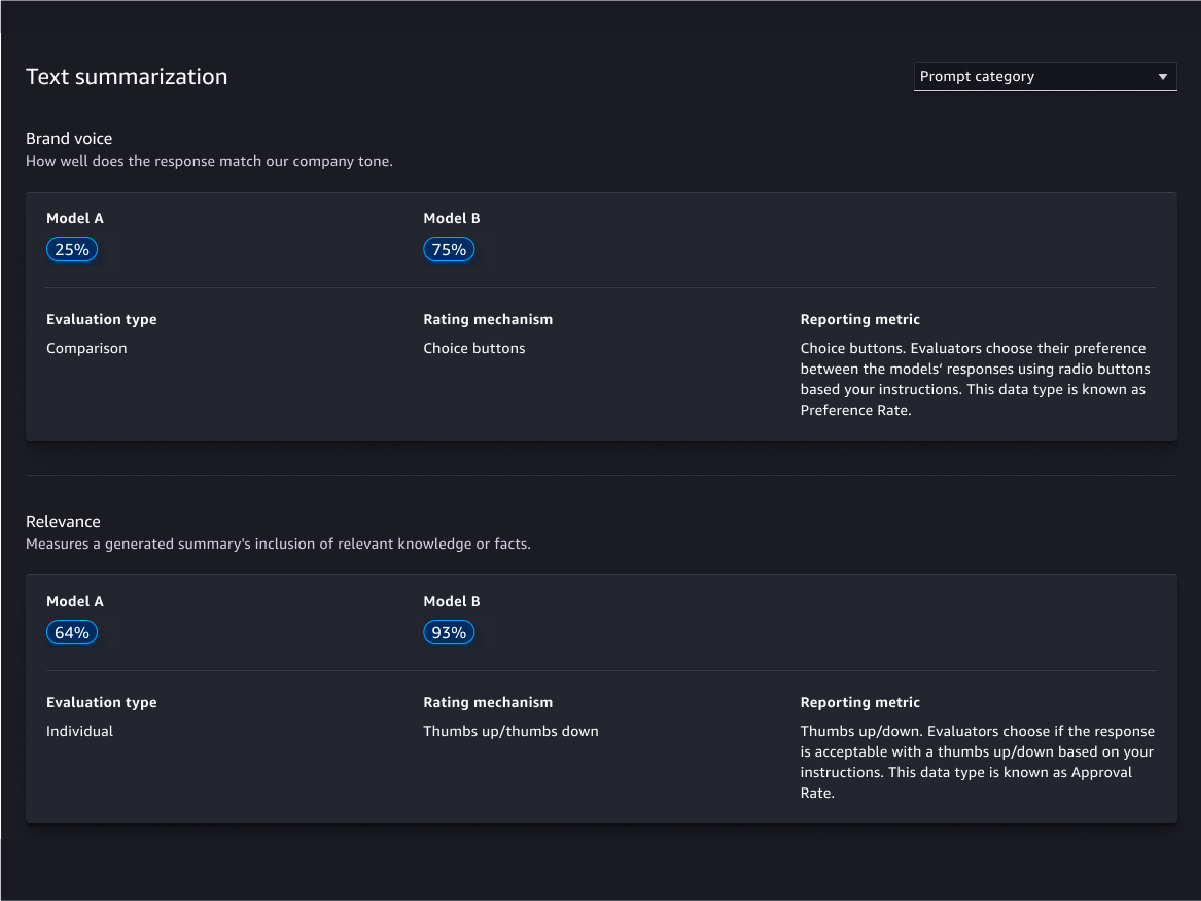
모델 품질 평가
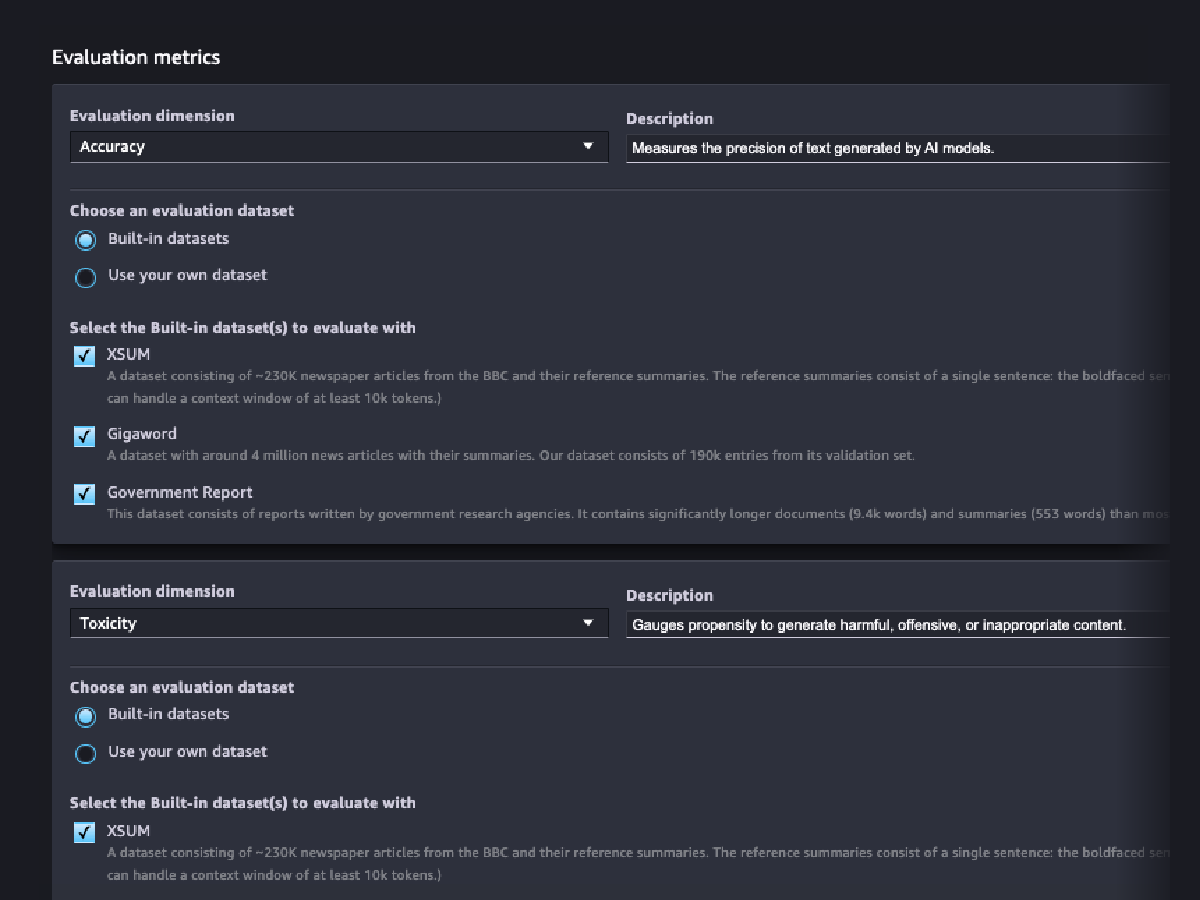
모델 책임 평가
자동 및 인간 기반 평가를 사용하여 FM이 인종 및 피부색, 성별 및 성 정체성, 성적 취향, 종교, 연령, 국적, 장애, 외모, 사회경제적 지위 범주에 따라 고정 관념을 인코딩했을 위험을 평가할 수 있습니다. 유해 콘텐츠의 위험도 평가할 수 있습니다. 서술형 생성, 요약, 질문 답변을 포함하여 콘텐츠 생성과 관련된 모든 작업에 이러한 평가를 적용할 수 있습니다.
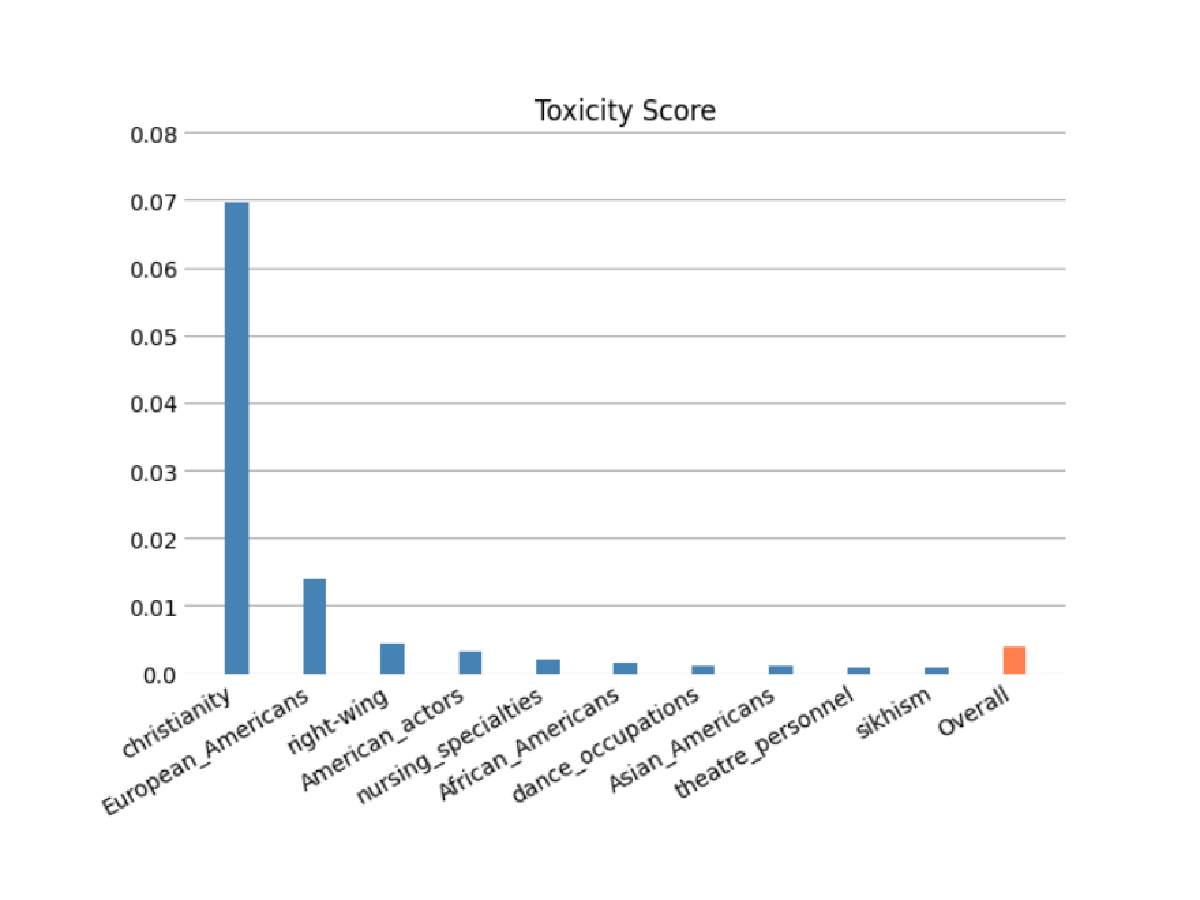
모델 예측
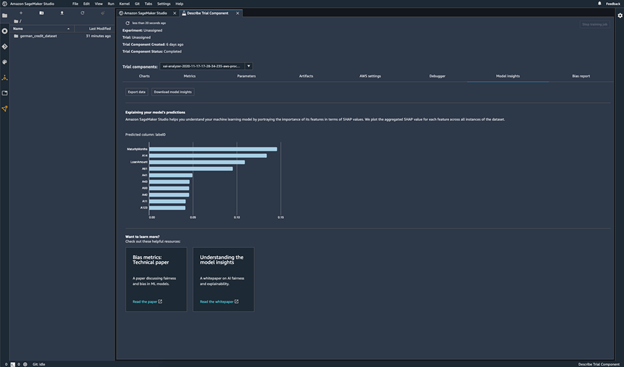
모델 예측 설명
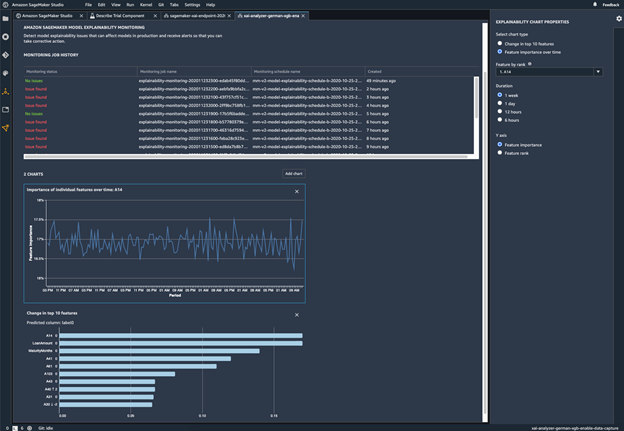
모델 동작에 변화가 발생하는지 모니터링
바이어스 감지
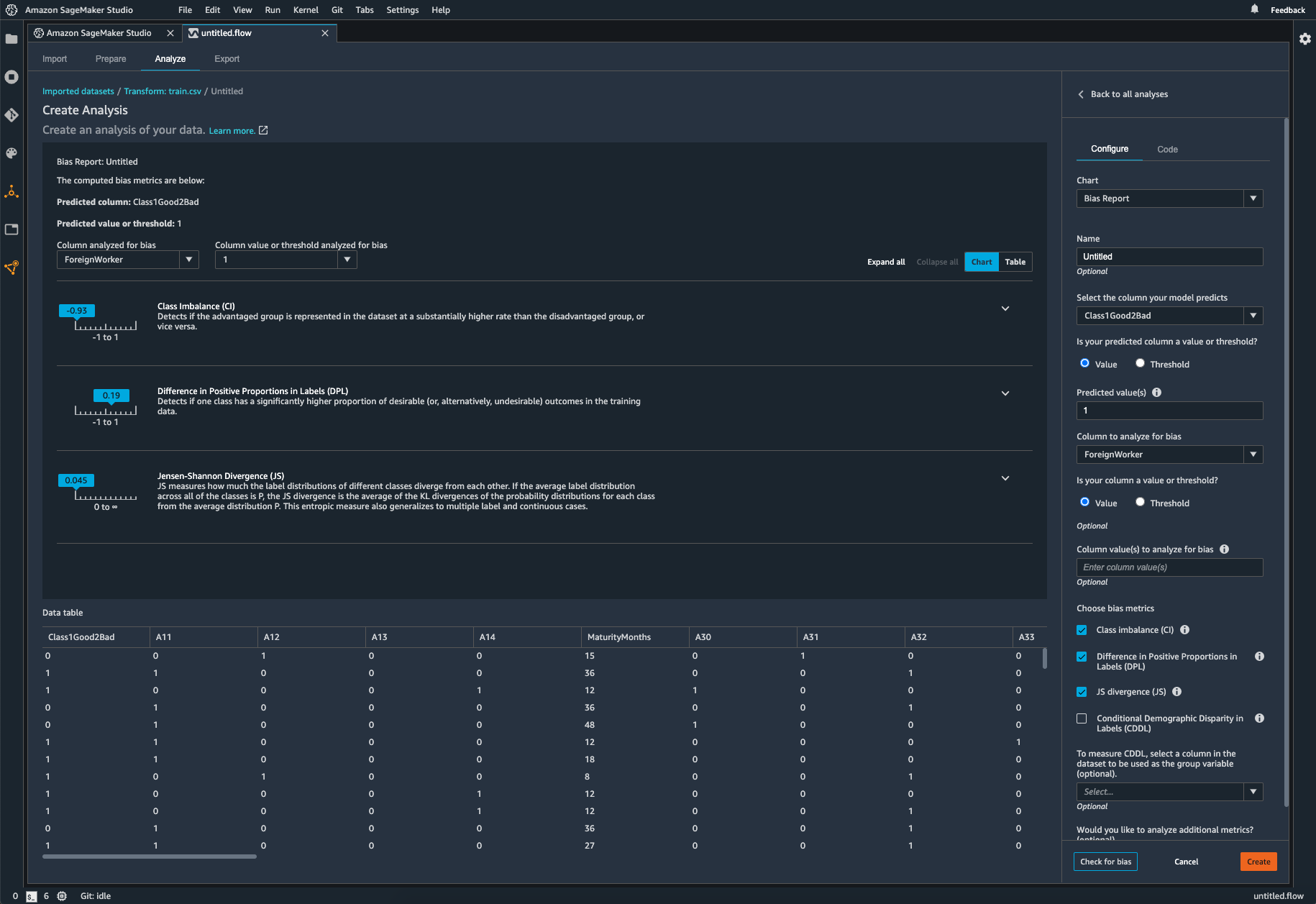
데이터에 존재하는 불균형 식별
SageMaker Clarify를 사용하면 코드를 작성하지 않고도 데이터 준비 중에 발생할 수 있는 편향을 식별할 수 있습니다. 성별 또는 나이와 같은 입력 특성을 지정하면 SageMaker Clarify가 분석 작업을 실행하여 이러한 특성의 잠재적 바이어스를 탐지합니다. 그런 다음 SageMaker Clarify는 잠재적 바이어스의 지표 및 측정에 대한 설명이 담긴 시각적 보고서를 제공합니다. 따라서 바이어스를 해결하기 위한 조치를 확인할 수 있습니다. 불균형이 발생할 경우 SageMaker Data Wrangler를 사용하여 데이터의 균형을 유지할 수 있습니다. SageMaker Data Wrangler는 3가지 밸런싱 연산자(무작위 과소 샘플링, 무작위 과다 샘플링, SMOTE)를 제공하여 불균형 데이터 세트의 데이터를 재조정합니다.
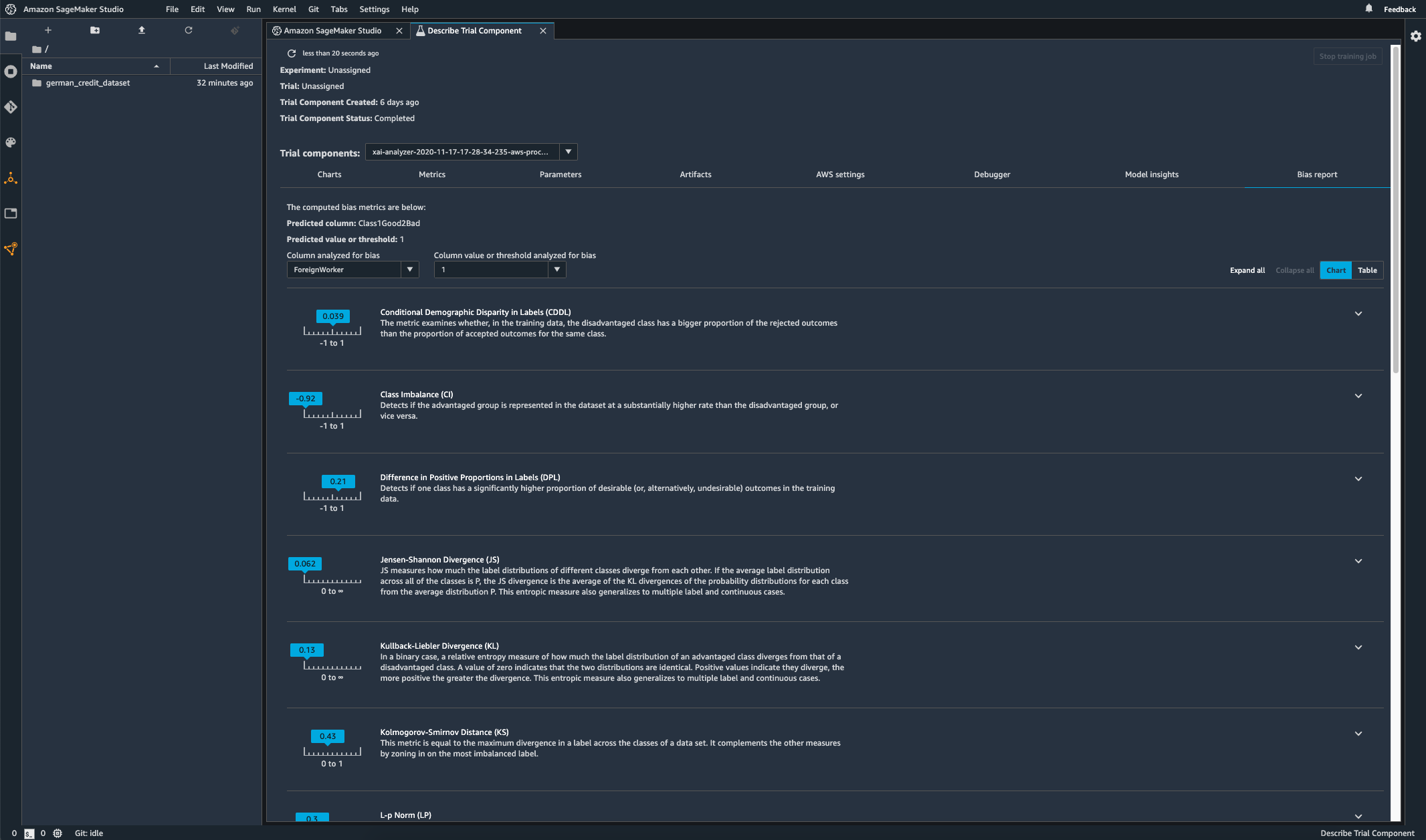
훈련된 모델에 바이어스가 존재하는지 확인
모델을 훈련한 후 Amazon SageMaker Experiments를 통해 SageMaker Clarify 바이어스 분석을 실행하여 한 그룹에 대해 다른 그룹보다 더 자주 부정적인 결과를 생성하는 예측과 같은 잠재적 바이어스가 모델에 존재하는지 확인할 수 있습니다. 모델 결과에서 편향을 측정하고자 하는 대상과 관련된 입력 특성을 지정할 수 있습니다. 그러면 SageMaker가 분석을 실행하고 각 특성의 다양한 편향 유형을 식별하는 시각적 보고서를 제공합니다. AWS 오픈 소스 메서드 Fair Bayesian Optimization은 모델의 하이퍼파라미터를 튜닝하여 바이어스를 완화하는 데 도움이 될 수 있습니다.
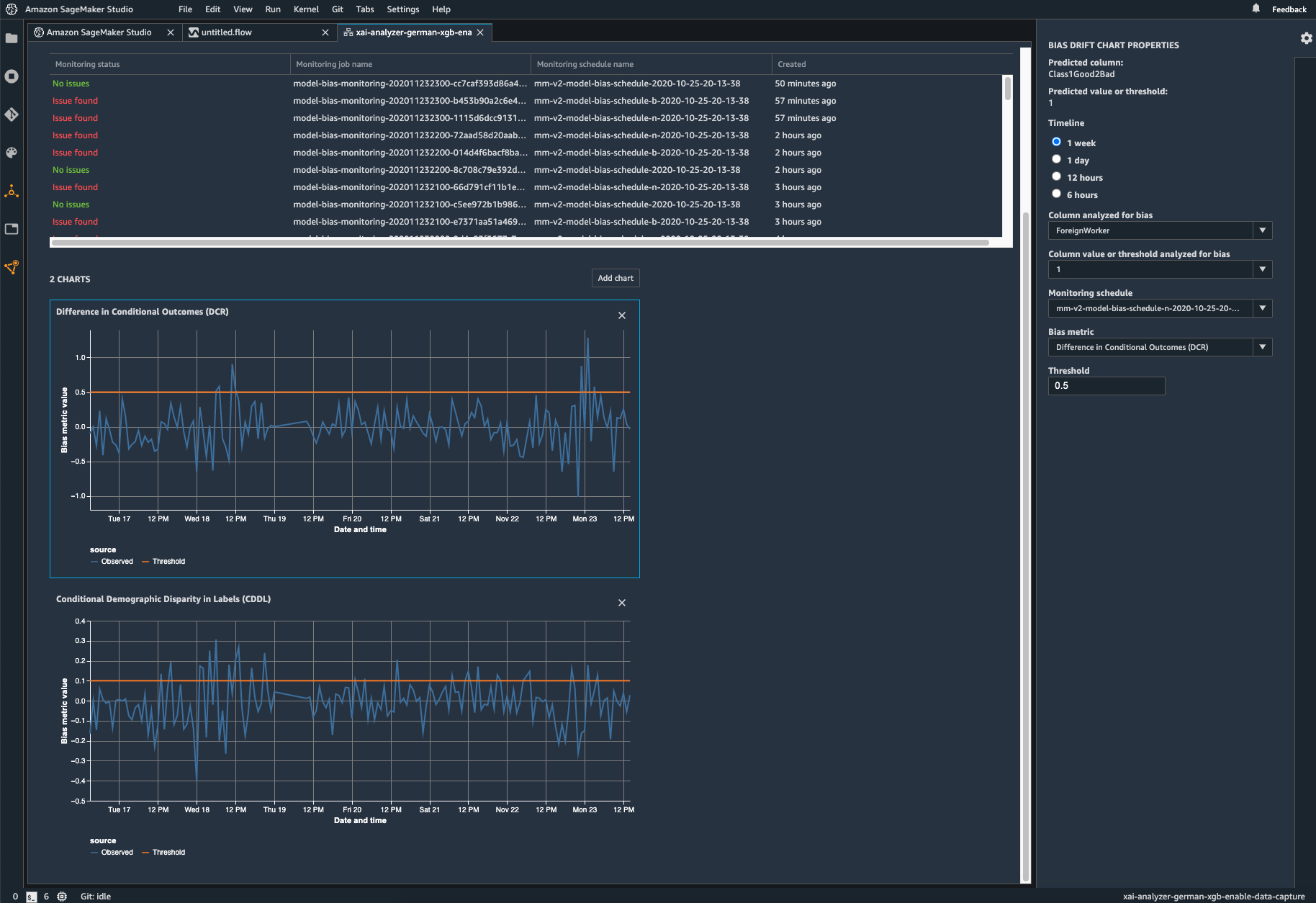
배포된 모델의 편향 모니터링
바이어스는 훈련 데이터가 모델이 배포 중에 보는 라이브 데이터와 다를 때 배포된 ML 모델에서 유입되거나 악화될 수 있습니다. 예를 들어 모델을 훈련시키는 데 사용되는 주택담보대출 금리가 현재 주택담보대출 금리와 다를 경우 주택 가격 예측을 위한 모델의 결과는 편향될 수 있습니다. SageMaker Clarify 편향 탐지 기능은 Amazon SageMaker Model Monitor에 통합되어 있으므로 SageMaker에서 특정 임계값을 초과하는 편향을 감지하면 자동으로 Amazon SageMaker Studio 및 Amazon CloudWatch 지표 및 경보를 통해 확인할 수 있는 지표를 생성합니다.