AWS Database Blog
Leverage pgvector and Amazon Aurora PostgreSQL for Natural Language Processing, Chatbots and Sentiment Analysis
March 2024: This post was reviewed and updated to include Amazon Bedrock models (Titan and Anthropic Claude).
Generative AI – a category of artificial intelligence algorithms that can generate new content based on existing data — has been hailed as the next frontier for various industries, from tech to financial services, e-commerce and healthcare. And indeed, we’re already seeing the many ways Generative AI is being adopted. ChatGPT is one example of Generative AI, a form of AI that does not require a background in machine learning (ML); virtually anyone with the ability to ask questions in simple English can utilize it. The driving force behind the capabilities of generative AI chatbots lies in their foundation models. These models consist of expansive neural networks meticulously trained on vast amounts of unstructured, unlabeled data spanning various formats, including text and audio. The versatility of foundation models enables their utilization across a wide range of tasks, showcasing their limitless potential. In this post, we cover two use cases in the context of pgvector and Amazon Aurora PostgreSQL-Compatible Edition:
- First, we build an AI-powered application that lets you ask questions based on content in your PDF files in natural language. We upload PDF files to the application and then type in questions in simple English. Our AI-powered application will process questions and return answers based on the content of the PDF files.
- Next, we make use of the native integration between pgvector and Amazon Aurora Machine Learning. Machine learning integration with Aurora currently supports Amazon Comprehend and Amazon SageMaker. Aurora makes direct and secure calls to SageMaker and Comprehend that don’t go through the application layer. Aurora machine learning is based on the familiar SQL programming language, so you don’t need to build custom integrations, move data around or learn separate tools.
Overview of pgvector and large language models (LLMs)
pgvector is an open-source extension for PostgreSQL that adds the ability to store and search over ML-generated vector embeddings. pgvector provides different capabilities that let you identify both exact and approximate nearest neighbors. It’s designed to work seamlessly with other PostgreSQL features, including indexing and querying. Using ChatGPT and other LLM tooling often requires storing the output of these systems, i.e., vector embeddings, in a permanent storage system for retrieval at a later time. In the previous post, Building AI-powered search in PostgreSQL using Amazon SageMaker and pgvector, we provided an overview of storing vector embeddings in PostgreSQL using pgvector, and a sample implementation for an online retail store.
Large language models (LLMs) have become increasingly powerful and capable. You can use these models for a variety of tasks, including generating text, chatbots, text summarization, image generation, and natural language processing capabilities such as answering questions. Some of the benefits offered by LLMs include the ability to create more capable and compelling conversational AI experiences for customer service applications or bots, and improving employee productivity through more intuitive and accurate responses. LangChain is a Python module that makes it simpler to use LLMs. LangChain provides a standard interface for accessing LLMs, and it supports a variety of LLMs, including OpenAI’s GPT series, Hugging Face, Google’s BERT, and Facebook’s RoBERTa.
Although LLMs offer many benefits for natural language processing (NLP) tasks, they may not always provide factual or precisely relevant responses to specific domain use cases. This limitation can be especially crucial for enterprise customers with vast enterprise data who require highly precise and domain-specific answers. For organizations seeking to improve LLM performance for their customized domains, they should look into effectively integrating their enterprise domain information into the LLM.
Solution overview
Use case 1: Build and deploy an AI-powered chatbot application
Prerequisites
- An Aurora PostgreSQL-Compatible Edition DB cluster with pgvector support.
- Access to Amazon Bedrock foundation models – Amazon Titan and Anthropic Claude.
- Install Python with the required dependencies (in this post, we use Python v3.9). You can deploy this solution locally on your laptop or via Amazon SageMaker Notebooks.
This solution incurs costs. Refer to Amazon Aurora Pricing to learn more.
How it works
Question answering (QA) is a crucial task that extracts factual answers from natural language queries. QA systems, typically processing queries against a knowledge base, aim for high accuracy to ensure reliability in enterprise applications. Generative AI models like Titan, Claude, and Jurassic use probability distributions but may not provide deterministic answers due to inherent uncertainty in data. LLMs are susceptible to hallucinations, generating false information. To address this, the Retrieval Augmented Generation (RAG) pattern is employed, which involves passing a user’s question and prompt as numerical representations to a vector database, enhancing the accuracy and consistency of responses.
We use Amazon Bedrock and Open Source LLMs with the pgvector extension on Amazon Aurora PostgreSQL-Compatible Edition as our vector store to demonstrate a Question Answering chatbot application with the RAG pattern. We retrieve the most up-to-date or context-specific data from our vector store and make it available to an LLM when asking it to generate a response. We also demonstrate integration with open-source frameworks such as LangChain for interfacing with all the components and Streamlit for building the Q/A chatbot frontend.
The following diagram illustrates how it works:

The application follows these steps to provide responses to your questions:
- PDF Loading: The app reads PDF documents and extracts their text content.
- Text Chunking: The extracted text is divided into smaller chunks that can be processed effectively.
- Embedding: The application utilizes Titan Text from Amazon Bedrock to generate vector representations (embeddings) of the text chunks.
- User Question: The user asks a question in natural language.
- Similarity Matching: When the user asks a question, the app compares it with the text chunks and identifies the most semantically similar ones.
- RAG: The user question and the context from the vector database is passed to the LLM (Anthropic’s Claude on Amazon Bedrock).
- Response Generation: The LLM generates a response based on the relevant content of the PDFs.
Environment setup
- Clone the GitHub repository to your local machine:
- Navigate to
aurora-postgresql-pgvector/02_RetrievalAugmentedGeneration/02_QuestionAnswering_Bedrock_LLMsfolder in terminal of your choice: - Create a
.envfile in your project directory to add your Aurora PostgreSQL DB cluster details. Your.envfile should like the following: - The GitHub repository you cloned earlier includes a file
requirements.txtwhich has all the required libraries you need to install for building the QnA chatbot application. Install the libraries by running the following commands:
Build the Streamlit application:
Note: To see the full implementation details about the code samples used in this blog post, please see the GitHub repo.
1. Import libraries
Let’s begin by importing the necessary libraries:

2. Take PDFs as input and extract text
This function takes a list of PDF documents as input and extracts the text from them using PdfReader. It concatenates the extracted text and returns it.
3. Split PDF(s) into chunks
Given the extracted text, this function splits it into smaller chunks using LangChain’s RecursiveCharacterTextSplitter module. The chunk size, overlap, and other parameters are configured to optimize processing efficiency.
4. Load vector embeddings into Amazon Aurora PostgreSQL
Next, you will load the vector embeddings using Amazon Bedrock’s Embedding model amazon.titan-embed-text-v1 into an Aurora PostgreSQL DB cluster as the vector database. This function takes the text chunks as input and creates a vector store using Bedrock Embeddings (Titan) and pgvector. Aurora PostgreSQL with the pgvector extension stores the vector representations of the text chunks, enabling efficient retrieval based on semantic similarity.
Note: PGVector needs the connection string to the database. You can create it from environment variables as shown in the screenshot below:

5. Create a Conversational Chain
In this function, a conversation chain is created using the conversational AI model (Anthropic’s Claude v2.1), vector store (created in the previous function), and conversation memory ConversationSummaryBufferMemory. This chain allows the generative AI application to engage in conversational interactions.
Let’s dive deeper on what’s going on:
Conversation Memory and Retrieval Chain
By default, LLMs are stateless, meaning that each incoming query is processed independently of other interactions. The only thing that exists for a stateless agent is the current input. There are many applications where remembering previous interactions is very important, such as chatbots. Conversational memory allows us to do that. LangChain’s ConversationSummaryBufferMemory and ConversationalRetrievalChain allow us to provide the user’s question and conversation history to generate the chatbot’s response while allowing room for follow-up questions.
Prompt Templates
The text that you give Claude is designed to elicit, or “prompt”, a relevant output. A prompt is usually in the form of a question or instructions. When prompting Claude through the API, it is very important to use the correct \n\nHuman: and \n\nAssistant: formatting.
Claude was trained as a conversational agent using these special tokens to mark who is speaking. The \n\nHuman: (you) asks a question or gives instructions, and the \n\nAssistant: (Claude) responds. For more information, please see: Introduction to prompt design.
6. Create a function to handle user input
This function is responsible for processing the user’s input question and generating a response from the chatbot.

7. Create the Streamlit components
Streamlit is an open-source Python library that makes it simple to create and share beautiful, custom web apps for machine learning and data science. In just a few minutes you can build and deploy powerful data apps.

Ensure there are no errors in your application.
Demonstration
Now that you have successfully written code for your generative AI chatbot application, it’s time to run the application via Streamlit.
Navigate to the folder aurora-postgresql-pgvector/02_RetrievalAugmentedGeneration/02_QuestionAnswering_Bedrock_LLMs
Run the following command:
If the command is successful, this is what the output screen will look like (note: we are using AWS Cloud9 terminal):

In Cloud9, you are able to preview a running application from within the IDE. Choose Preview -> Preview Running Application from the menu bar:

The Preview screen appears as follows:

Follow the instructions in the sidebar:
- Browse and upload PDF files. You can upload multiple PDFs because we set the parameter
accept_multiple_files=Truefor thefile_uploaderfunction. - Let’s upload a PDF – Amazon Aurora FAQs. Download/save this file and upload it to your Streamlit application by clicking Browse files. Once you’ve uploaded the file, click Process. Once the PDF is uploaded successfully, you will see a PDF uploaded successfully.


- Start asking your questions in the text input box. For example, let’s start with a simple question –
What is Amazon Aurora?

- Let’s ask a different question, a bit more complex –
What does "three times the performance of PostgreSQL" mean?
Note: you may either see a similar or a slightly different response:

Note here that without specifying the keyword “Aurora”, our generative AI app took the context from the previous question and inferred that the question was in fact about Amazon Aurora PostgreSQL-Compatible Edition. This is because the chat/conversation history is preserved due to LangChain’s ConversationSummaryBufferMemory. Also, ConversationalRetrievalChain allows you to set up a chain with chat history for follow-up questions.
- With Streamlit, you can also upload multiple files as sources and ask questions from any of those sources. But before we upload our new file, let’s ask a question for which our LLM doesn’t have any context yet –
What is Amazon Bedrock?
Note the response (you may either see a similar or a slightly different response):

- Now, let’s upload another file Amazon Bedrock FAQs. Download/save this file, click Browse files to upload this file and then click Process. Once the PDF is uploaded successfully, you will see a PDF uploaded successfully
Now, let’s ask our chatbot the previous question. A response similar to the following is generated:

- Try out some more questions and see the results:
- Which FMs are available on Amazon Bedrock?
- Why should I use Amazon Bedrock?
- What are Amazon Bedrock Agents?
- How can I connect FMs to my company data sources?
- How can I securely use my data to customize FMs available through Amazon Bedrock?
Feel free to play around, upload more PDF files and ask more questions as practice. Streamlit and LangChain are extremely easy and well suited for creating generative AI applications.
For full implementation details about the code samples used in the post, see the GitHub repo.
Use Case 2: pgvector and Aurora Machine Learning for Sentiment Analysis
Prerequisites
- Aurora PostgreSQL v15.3 with pgvector support.
- Install Python with the required dependencies (in this post, we use Python v3.9).
- Jupyter (available as an extension on VS Code or through Amazon SageMaker Notebooks).
- AWS CLI installed and configured for use. For instructions, see Set up the AWS CLI.
This solution incurs costs. Refer to Amazon Aurora Pricing to learn more.
Amazon Comprehend is a natural language processing (NLP) service that uses machine learning to find insights and relationships in text. No prior machine learning experience is required. This example will walk you through the process of integrating Aurora with the Comprehend Sentiment Analysis API and making sentiment analysis inferences via SQL commands. For our example, we have used a sample dataset for fictitious hotel reviews. We use Hugging Face’s sentence-transformers/all-mpnet-base-v2 model for generating document embeddings and store vector embeddings in our Aurora PostgreSQL DB cluster with pgvector.
Use Amazon Comprehend with Amazon Aurora
- Create an IAM role to allow Aurora to interface with Comprehend.
- Associate the IAM role with the Aurora DB cluster.
- Install the
aws_mland vector extensions. For installing theaws_mlextension, see Installing the Aurora machine learning extension. - Setup the required environment variables.
- Run through each cell in the given notebook
pgvector_with_langchain_auroraml.ipynb. - Run Comprehend inferences from Aurora.
1. Create an IAM role to allow Aurora to interface with Comprehend
Run the following commands to create and attach an inline policy to the IAM role we just created:
2. Associate the IAM role with the Aurora DB cluster
Associate the role with the DB cluster by using following command:
Run the following command and wait until the output shows as available, before moving on to the next step:
Validate that the IAM role is active by running the following command:
You should see an output similar to the following:

For more information or instructions on how to perform steps 1 and 2 using the AWS Console see: Setting up Aurora PostgreSQL to use Amazon Comprehend.
3. Connect to psql or your favorite PostgreSQL client and install the extensions
4. Setup the required environment variables
We use VS Code for this example. Create a .env file with the following environment variables:
5. Run through each cell in the given notebook pgvector_with_langchain_auroraml.ipynb
- Import libraries
Begin by importing the necessary libraries:
- Use LangChain’s CSVLoader library to load CSV and generate embeddings using Hugging Face sentence transformers:
If the run is successful, you should see an output as follows:
- Split the text using LangChain’s CharacterTextSplitter function and generate chunks:
If the run is successful, you should see an output as follows:
- Create a table in Aurora PostgreSQL with the name of the collection. Make sure that the collection name is unique and the user has the permissions to create a table:
Run a similarity search using the similarity_search_with_score function from pgvector.
If the run is successful, you should see an output as follows:
- Use the Cosine function to refine the results to the best possible match:
If the run is successful, you should see an output as follows:
Similarly, you can test results with other distance strategies such as Euclidean or Max Inner Product. Euclidean distance depends on a vector’s magnitude whereas cosine similarity depends on the angle between the vectors. The angle measure is more resilient to variations of occurrence counts between terms that are semantically similar, whereas the magnitude of vectors is influenced by occurrence counts and heterogeneity of word neighborhood. Hence for similarity searches or semantic similarity in text, the cosine distance gives a more accurate measure.
6. Run Comprehend inferences from Aurora
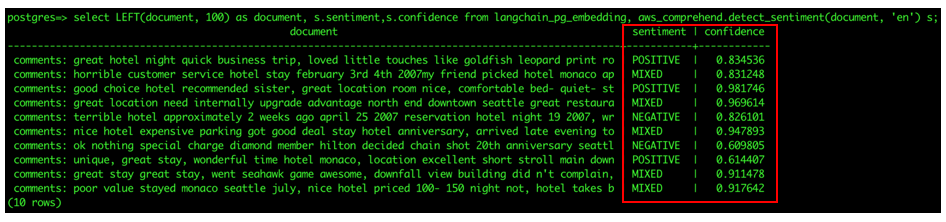
Aurora has a built-in Comprehend function which can call the Comprehend service. It passes the inputs of the aws_comprehend.detect_sentiment function, in this case the values of the document column in the langchain_pg_embedding table, to the Comprehend service and retrieves sentiment analysis results (note that the document column is trimmed due to the long free form nature of reviews):
You should see results as shown in the screenshot below. Observe the columns sentiment, and confidence. The combination of these two columns provide the inferred sentiment for the text in the document column, and also the confidence score of the inference.
For full implementation details about the code sample used in the post, see the GitHub repo.
Conclusion
In this post, we explored how to build an interactive chatbot app for question answering using LangChain and Streamlit and leveraged pgvector and its native integration with Aurora Machine Learning for sentiment analysis. With this sample chatbot app, users can input their questions and receive answers based on the provided information, making it a useful tool for information retrieval and knowledge exploration, especially in large enterprises with a massive knowledge corpus. The integration of embeddings generated using LangChain and storing them in Amazon Aurora PostgreSQL-Compatible Edition with the pgvector open-source extension for PostgreSQL presents a powerful and efficient solution for many use cases such as sentiment analysis, fraud detection and product recommendations.
Now Available
The pgvector extension is available on Aurora PostgreSQL 15.3, 14.8, 13.11, 12.15 and higher in AWS Regions including the AWS GovCloud (US) Regions.
If you are interested in learning more about this launch, you can watch our team’s demo on AWS On Air.
If you have questions or suggestions, leave a comment.
We have adapted the concepts from this post into a deployable solution, now available as Guidance for High-Speed RAG Chatbots on AWS and Guidance for Sentiment Analysis on AWS in the AWS Solutions Library. To get started, review the architecture diagrams and the corresponding AWS Well-Architected framework, then deploy the sample code to implement the Guidance into your workloads.
About the Author
 Shayon Sanyal is a Principal Database Specialist Solutions Architect and a Subject Matter Expert for Amazon’s flagship relational database, Amazon Aurora. He has over 15 years of experience managing relational databases and analytics workloads. Shayon’s relentless dedication to customer success allows him to help customers design scalable, secure and robust cloud native architectures. Shayon also helps service teams with design and delivery of pioneering features.
Shayon Sanyal is a Principal Database Specialist Solutions Architect and a Subject Matter Expert for Amazon’s flagship relational database, Amazon Aurora. He has over 15 years of experience managing relational databases and analytics workloads. Shayon’s relentless dedication to customer success allows him to help customers design scalable, secure and robust cloud native architectures. Shayon also helps service teams with design and delivery of pioneering features.