AWS Compute Blog
Enriching Event-Driven Architectures with AWS Event Fork Pipelines
September 8, 2021: Amazon Elasticsearch Service has been renamed to Amazon OpenSearch Service. See details.
This post is courtesy of Otavio Ferreira, Mgr, Amazon SNS, and James Hood, Sr. Software Dev Engineer
Many customers are choosing to build event-driven applications in which subscriber services automatically perform work in response to events triggered by publisher services. This architectural pattern can make services more reusable, interoperable, and scalable.
These customers often fork event processing into pipelines that address common event handling requirements, such as event storage, backup, search, analytics, or replay. To help you build event-driven applications even faster, AWS introduces Event Fork Pipelines, a collection of open-source event handling pipelines that you can subscribe to Amazon SNS topics in your AWS account.
Event Fork Pipelines is a suite of open-source nested applications, based on the AWS Serverless Application Model (AWS SAM). You can deploy it directly from the AWS Serverless Application Repository into your AWS account.
Event Fork Pipelines is built on top of serverless services, including Amazon SNS, Amazon SQS, and AWS Lambda. These services provide serverless building blocks that help you build fully managed, highly available, and scalable event-driven platforms. Lambda enables you to build event-driven microservices as serverless functions. SNS and SQS provide serverless topics and queues for integrating these microservices and other distributed systems in your architecture. These building blocks are at the core of the modern application development best practices.
Surfacing the event fork pattern
At AWS, we’ve worked closely with customers across market segments and geographies on event-driven architectures. For example:
- Financial platforms that handle events related to bank transactions and stock ticks
- Retail platforms that trigger checkout and fulfillment events
At scale, event-driven architectures often require a set of supporting services to address common requirements such as system auditability, data discoverability, compliance, business insights, and disaster recovery. Translated to AWS, customers often connect event-driven applications to services such as Amazon S3 for event storage and backup, and to Amazon Elasticsearch Service for event search and analytics. Also, customers often implement an event replay mechanism to recover from failure modes in their applications.
AWS created Event Fork Pipelines to encapsulate these common requirements, reducing the amount of effort required for you to connect your event-driven architectures to these supporting AWS services.
AWS then started sharing this pattern more broadly, so more customers could benefit. At the 2018 AWS re:Invent conference in Las Vegas, Amazon CTO Werner Vogels announced the launch of nested applications in his keynote. Werner shared the Event Fork Pipelines pattern with the audience as an example of common application logic that had been encapsulated as a set of nested applications.
The following reference architecture diagram shows an application supplemented by three nested applications:
Each pipeline is subscribed to the same SNS topic, and can process events in parallel as these events are published to the topic. Each pipeline is independent and can set its own subscription filter policy. That way, it processes only the subset of events that it’s interested in, rather than all events published to the topic.

Figure 1 – Reference architecture using Event Fork Pipelines
The three event fork pipelines are placed alongside your regular event processing pipelines, which are potentially already subscribed to your SNS topic. Therefore, you don’t have to change any portion of your current message publisher to take advantage of Event Fork Pipelines in your existing workloads. The following sections describe these pipelines and how to deploy them in your system architecture.
Understanding the catalog of event fork pipelines
In the abstract, Event Fork Pipelines is a serverless design pattern. Concretely, Event Fork Pipelines is also a suite of nested serverless applications, based on AWS SAM. You deploy the nested applications directly from the AWS Serverless Application Repository to your AWS account, to enrich your event-driven platforms. You can deploy them individually in your architecture, as needed.
Here’s more information about each nested application in the Event Fork Pipelines suite.
Event Storage & Backup pipeline

Figure 2 – Event Fork Pipeline for Event Storage & Backup
The preceding diagram shows the Event Storage & Backup pipeline. You can subscribe this pipeline to your SNS topic to automatically back up the events flowing through your system. This pipeline is composed of the following resources:
- An SQS queue that buffers the events delivered by the SNS topic
- A Lambda function that automatically polls for these events in the queue and pushes them into an Amazon Kinesis Data Firehose delivery stream
- An S3 bucket that durably backs up the events loaded by the stream
You can configure this pipeline to fine-tune the behavior of your delivery stream. For example, you can configure your pipeline so that the underlying delivery stream buffers, transforms, and compresses your events before loading them into the bucket. As events are loaded, you can use Amazon Athena to query the bucket using standard SQL queries. Also, you can configure the pipeline to either reuse an existing S3 bucket or create a new one for you.
Event Search & Analytics pipeline

Figure 3 – Event Fork Pipeline for Event Search & Analytics
The preceding diagram shows the Event Search & Analytics pipeline. You can subscribe this pipeline to your SNS topic to index in a search domain the events flowing through your system, and then run analytics on them. This pipeline is composed of the following resources:
- An SQS queue that buffers the events delivered by the SNS topic
- A Lambda function that polls events from the queue and pushes them into a Data Firehose delivery stream
- An Amazon ES domain that indexes the events loaded by the delivery stream
- An S3 bucket that stores the dead-letter events that couldn’t be indexed in the search domain
You can configure this pipeline to fine-tune your delivery stream in terms of event buffering, transformation and compression. You can also decide whether the pipeline should reuse an existing Amazon ES domain in your AWS account or create a new one for you. As events are indexed in the search domain, you can use Kibana to run analytics on your events and update visual dashboards in real time.
Event Replay pipeline

Figure 4 – Event Fork Pipeline for Event Replay
The preceding diagram shows the Event Replay pipeline. You can subscribe this pipeline to your SNS topic to record the events that have been processed by your system for up to 14 days. You can then reprocess them in case your platform is recovering from a failure or a disaster. This pipeline is composed of the following resources:
- An SQS queue that buffers the events delivered by the SNS topic
- A Lambda function that polls events from the queue and redrives them into your regular event processing pipeline, which is also subscribed to your topic
By default, the replay function is disabled, which means it isn’t redriving your events. If the events need to be reprocessed, your operators must enable the replay function.
Applying event fork pipelines in a use case
This is how everything comes together. The following scenario describes an event-driven, serverless ecommerce application that uses the Event Fork Pipelines pattern. This example ecommerce application is available in AWS Serverless Application Repository. You can deploy it to your AWS account using the Lambda console, test it, and look at its source code in GitHub.
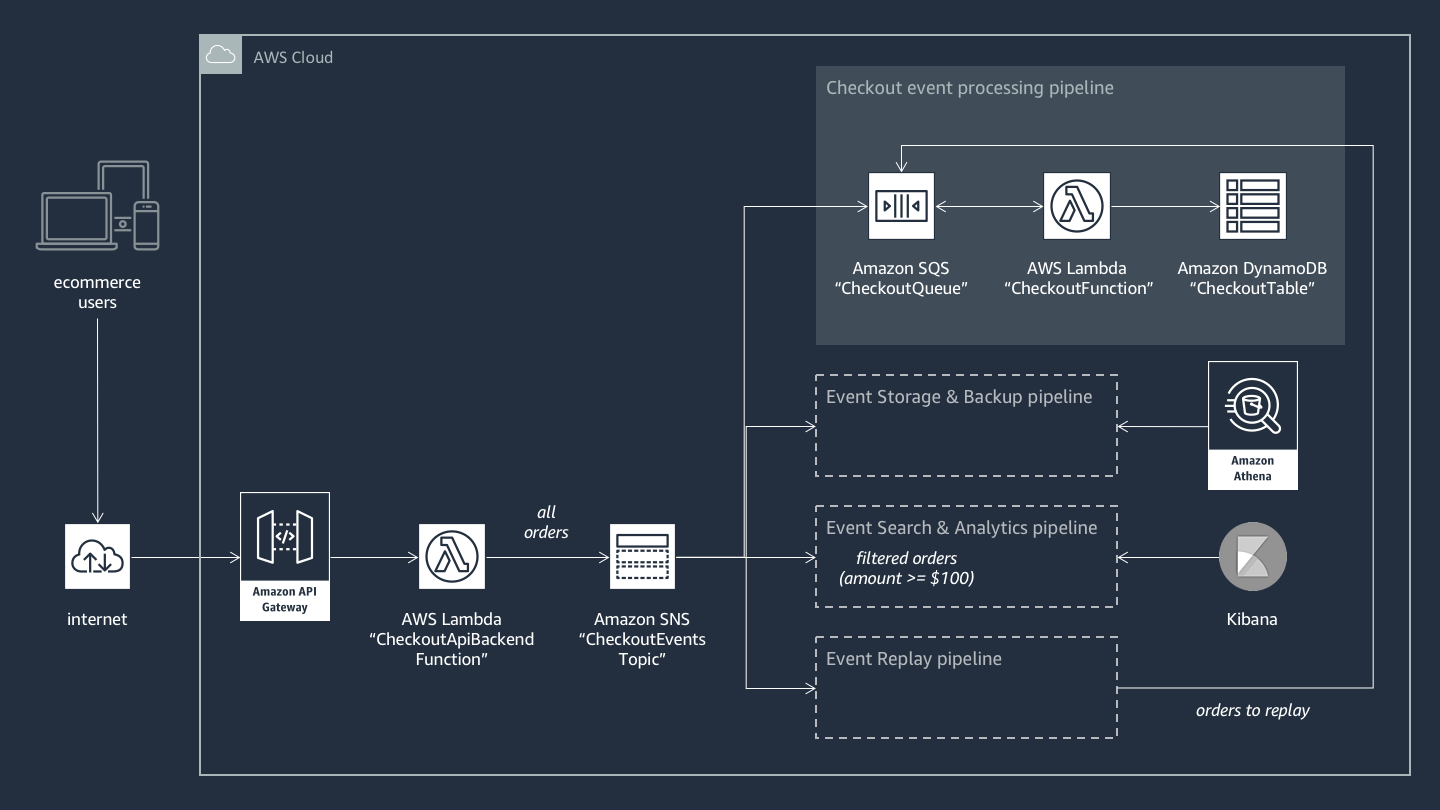
Figure 5 – Example e-commerce application using Event Fork Pipelines
The ecommerce application takes orders from buyers through a RESTful API hosted by Amazon API Gateway and backed by a Lambda function named CheckoutApiBackendFunction. This function publishes all orders received to an SNS topic named CheckoutEventsTopic, which in turn fans out the orders to four different pipelines. The first pipeline is the regular checkout-processing pipeline designed and implemented by you as the ecommerce application owner. This pipeline has the following resources:
- An SQS queue named CheckoutQueue that buffers all orders received
- A Lambda function named CheckoutFunction that polls the queue to process these orders
- An Amazon DynamoDB table named CheckoutTable that securely saves all orders as they’re placed
The components of the system described thus far handle what you might think of as the core business logic. But in addition, you should address the set of elements necessary for making the system resilient, compliant, and searchable:
- Backing up all orders securely. Compressed backups must be encrypted at rest, with sensitive payment details removed for security and compliance purposes.
- Searching and running analytics on orders, if the amount is $100 or more. Analytics are needed for key ecommerce metrics, such as average ticket size, average shipping time, most popular products, and preferred payment options.
- Replaying recent orders. If the fulfillment process is disrupted at any point, you should be able to replay the most recent orders from up to two weeks. This is a key requirement that guarantees the continuity of the ecommerce business.
Rather than implementing all the event processing logic yourself, you can choose to subscribe Event Fork Pipelines to your existing SNS topic . The pipelines are configured as follows:
- The Event Storage & Backup pipeline is configured to transform data as follows:
- Remove credit card details
- Buffer data for 60 seconds
- Compress data using GZIP
- Encrypt data using the default customer master key (CMK) for S3
This CMK is managed by AWS and powered by AWS Key Management Service (AWS KMS). For more information, see Choosing Amazon S3 for Your Destination, Data Transformation, and Configuration Settings in the Amazon Kinesis Data Firehose Developer Guide.
- The Event Search & Analytics pipeline is configured with:
- An index retry duration of 30 seconds
- A bucket for storing orders that failed to be indexed in the search domain
- A filter policy to restrict the set of orders that are indexed
For more information, see Choosing Amazon ES for Your Destination, in the Amazon Kinesis Data Firehose Developer Guide.
- The Event Replay pipeline is configured with the SQS queue name that is part of the regular checkout processing pipeline. For more information, see Queue Name and URL in the Amazon SQS Developer Guide.
The filter policy, shown in JSON format, is set in the configuration for the Event Search & Analytics pipeline. This filter policy matches only incoming orders in which the total amount is $100 or more. For more information, see Message Filtering in the Amazon SNS Developer Guide.
{
"amount": [
{ "numeric": [ ">=", 100 ] }
]
}By using the Event Fork Pipelines pattern, you avoid the development overhead associated with coding undifferentiated logic for handling events.
Event Fork Pipelines can be deployed directly from AWS Serverless Application Repository into your AWS account.
Deploying event fork pipelines
Event Fork Pipelines is available as a set of public apps in the AWS Serverless Application Repository (to find the apps, select the ‘Show apps that create custom IAM roles or resource policies’ check box under the search bar). It can be deployed and tested manually via the Lambda console. In a production scenario, we recommend embedding fork pipelines within the AWS SAM template of your overall application. The nested applications feature enables you to do this by adding an AWS::Serverless::Application resource to your AWS SAM template. The resource references the ApplicationId and SemanticVersion values of the application to nest.
For example, you can include the Event Storage & Backup pipeline as a nested application by adding the following YAML snippet to the Resources section of your AWS SAM template:
Backup:
Type: AWS::Serverless::Application
Properties:
Location:
ApplicationId: arn:aws:serverlessrepo:us-east-1:012345678901:applications/fork-event-storage-backup-pipeline
SemanticVersion: 1.0.0
Parameters:
# SNS topic ARN whose messages should be backed up to the S3 bucket.
TopicArn: !Ref MySNSTopicWhen specifying parameter values, you can use AWS CloudFormation intrinsic functions to reference other resources in your template. In the preceding example, the TopicArn parameter is filled in by referencing an AWS::SNS::Topic called MySNSTopic, defined elsewhere in the AWS SAM template. For more information, see Intrinsic Function Reference in the AWS CloudFormation User Guide.
To copy the YAML required for nesting, in the Lambda console page for an AWS Serverless Application Repository application, choose Copy as SAM Resource.
Authoring new event fork pipelines
We invite you to fork the Event Fork Pipelines repository in GitHub and submit pull requests for contributing with new pipelines. In addition to event storage and backup, event search and analytics, and event replay, what other common event handling requirements have you seen?
We look forward to seeing what you’ll come up with for extending the Event Fork Pipelines suite.
Summary
Event Fork Pipelines is a serverless design pattern and a suite of open-source nested serverless applications, based on AWS SAM. You can deploy it directly from AWS Serverless Application Repository to enrich your event-driven system architecture. Event Fork Pipelines lets you store, back up, replay, search, and run analytics on the events flowing through your system. There’s no need to write code, manually stitch resources together, or set up infrastructure.
You can deploy Event Fork Pipelines in any AWS Region that supports the underlying AWS services used in the pipelines. There are no additional costs associated with Event Fork Pipelines itself, and you pay only for using the AWS resources inside each nested application.
Get started today by deploying the example ecommerce application or searching for Event Fork Pipelines in AWS Serverless Application Repository.