



Che cos'è l'architettura dei dati?
L'architettura dei dati è il framework generale che descrive e disciplina la raccolta, la gestione e l'utilizzo dei dati di un'organizzazione. Oggi le organizzazioni dispongono di enormi volumi di dati provenienti da diverse origini e di team eterogenei che desiderano accedere a tali dati per analisi, machine learning, intelligenza artificiale e altre applicazioni. L'architettura moderna dei dati presenta un sistema coeso che rende i dati accessibili e utilizzabili, garantendone al contempo la sicurezza e la qualità. Definisce policy, modelli di dati, processi e tecnologie che consentono alle organizzazioni di spostare facilmente i dati tra i reparti e di garantire che siano disponibili ogni volta che servono, incluso l'accesso in tempo reale, supportando al contempo la piena conformità normativa.
Quali sono i componenti di un'architettura dei dati?
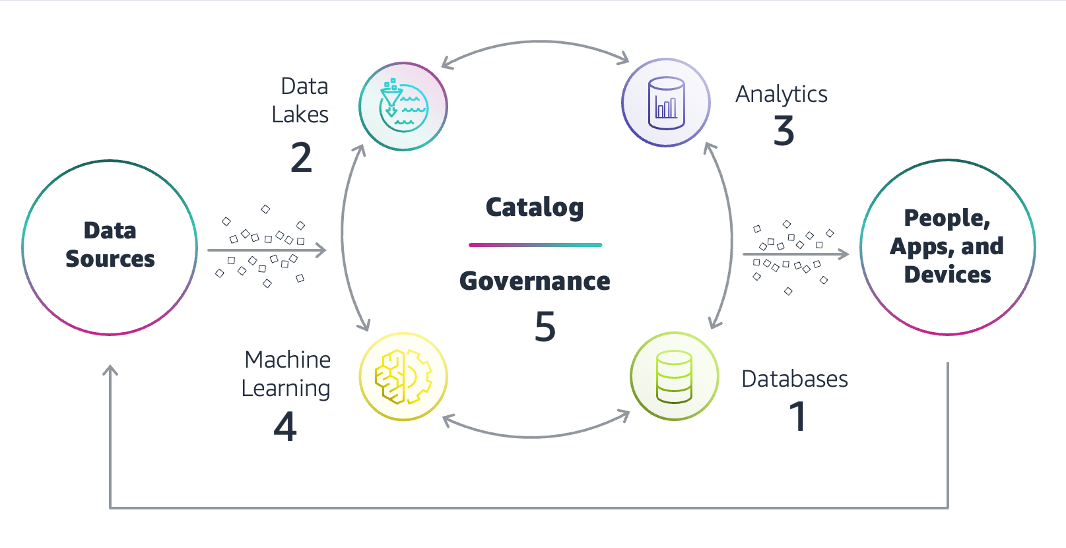
Di seguito sono riportati i principali componenti dell'architettura dei dati.
Origini dati
Le origini dati possono essere applicazioni rivolte ai clienti, sistemi di monitoraggio e telemetria, dispositivi IoT e sensori intelligenti, app a supporto delle operazioni aziendali, knowledge store interni, archivi di dati, archivi di dati di terze parti e altro ancora. I dati strutturati e non strutturati entrano nell'organizzazione a velocità, volumi e frequenze variabili.
Database
I sistemi di database dedicati supportano le applicazioni moderne e le loro diverse funzionalità. Possono essere relazionali o non relazionali: alcuni archiviano dati come tabelle strutturate, mentre altri archiviano tipi di dati non strutturati come documenti o coppie chiave-valore. I database in genere archiviano i dati specifici di un dominio, relativi a un caso d'uso ristretto. Tuttavia, i dati possono essere utilizzati anche al di fuori del sistema attuale. Ad esempio, i dati provenienti da un'app rivolta ai clienti possono essere utilizzati per analisi o pianificazioni di marketing e devono essere estratti dal database per essere elaborati. Allo stesso modo, i dati elaborati da altre origini devono essere ricaricati nel database di un'applicazione di analisi o machine learning (ML).
Data lake
Un data lake è un repository centralizzato per l'archiviazione di dati non elaborati su larga scala. L'architettura dei dati descrive come i dati vengono spostati da diversi database al data lake e viceversa, a seconda delle necessità di utilizzo. Il data lake archivia i dati in un formato nativo o aperto, consentendone la formattazione e la pulizia prima dell'uso. Supporta l'integrazione dei dati e abbatte i silo di dati all'interno di un'organizzazione.
Analisi di dati
Il componente di analisi dei dati include data warehouse tradizionali, report in batch e tecnologia di streaming dei dati per avvisi e report in tempo reale. Possono essere utilizzati per eseguire query una tantum e per casi d'uso di analisi avanzate. L'analisi non è vincolata dai silo di dati perché l'architettura dei dati apre l'accesso e consente a tutti una maggiore libertà di utilizzare le risorse di dati dell'organizzazione.
Intelligenza artificiale
Il ML e l'IA sono fondamentali per una moderna strategia dei dati, al fine di aiutare le organizzazioni a prevedere gli scenari futuri e a integrare l'intelligenza nelle applicazioni. I data scientist utilizzano i dati provenienti dai data lake per sperimentare, identificare casi d'uso dell'intelligence e addestrare nuovi modelli. Anche dopo l'addestramento, i modelli di intelligenza artificiale necessitano di un accesso continuo a dati aggiornati per generare output pertinenti e utili. Le moderne architetture di dati includono tutta la tecnologia e l'infrastruttura che supportano l'addestramento e l'inferenza dei modelli di intelligenza artificiale.
Governance dei dati
La governance dei dati determina ruoli, responsabilità e standard per l'utilizzo dei dati. Delinea chi può intraprendere quali operazioni, su quali dati, utilizzando quali metodi e in quali situazioni. Include la gestione della qualità e della sicurezza dei dati. Gli architetti dei dati definiscono i processi per verificare e monitorare l'utilizzo dei dati ai fini della continua conformità normativa.
La gestione dei metadati è parte integrante della governance dei dati. L'architettura dei dati include strumenti e policy per archiviare e condividere i metadati. Descrive i meccanismi per fornire un archivio centrale di metadati in cui sistemi diversi possono archiviare e scoprire i metadati e utilizzarli per ulteriori query ed elaborazioni di risorse di dati.
Come viene implementata l'architettura dei dati?
È consigliabile implementare la moderna architettura dei dati a più livelli. I livelli raggruppano processi e tecnologie in base a obiettivi distinti. I dettagli dell'implementazione sono flessibili, ma i livelli guidano le scelte tecnologiche e il modo in cui devono essere integrate.

Livello di staging
Il livello di staging è il punto di ingresso dei dati all'interno dell'architettura. Gestisce l'importazione di dati non elaborati da varie origini, inclusi formati strutturati, semi-strutturati e non strutturati. Questo livello deve essere il più flessibile possibile.
Se lo schema (formati e tipi di dati) viene applicato rigidamente a questo livello, i casi d'uso a valle diventano limitati. Ad esempio, l'applicazione del formato mese, anno per tutti i valori delle date limita i casi di utilizzo futuri che richiedono la formattazione gg/mm/aaaa. Allo stesso tempo, è necessario che ci sia una certa coerenza. Ad esempio, se i numeri di telefono vengono archiviati come stringhe e utilizzati come tali, ma un'altra origine dati inizia a generare gli stessi dati numerici, si verifica l'interruzione delle pipeline di dati.
Per bilanciare flessibilità e coerenza è necessario dividere questo livello in due sottolivelli.
Livello non elaborato
Il livello non elaborato memorizza i dati inalterati esattamente come arrivano, preservando il formato e la struttura originali senza trasformazioni. Si tratta di un archivio aziendale per l'esplorazione, l'audit e la riproducibilità dei dati. Quando necessario, i team possono riesaminare e analizzare i dati nel loro stato originale, garantendo trasparenza e tracciabilità.
Livello standardizzato
Il livello standardizzato prepara i dati non elaborati per il consumo applicando convalide e trasformazioni secondo standard predefiniti. Ad esempio, in questo livello, tutti i numeri di telefono verrebbero convertiti in stringhe, tutti i valori temporali in formati specifici, ecc. Diventa quindi l'interfaccia tramite cui tutti gli utenti all'interno dell'organizzazione possono accedere a dati strutturati e di qualità garantita.
Il livello standardizzato nell'architettura dei dati è fondamentale per abilitare la business intelligence (BI) self-service, l'analisi di routine e i flussi di lavoro di ML. Applica gli standard dello schema riducendo al minimo le interruzioni causate dalle modifiche dello schema.
Livello conformato
L'integrazione dei dati provenienti da diverse origini viene completata nel livello conformato. Crea un modello di dati aziendali unificato tra i domini. Ad esempio, i dati dei clienti possono avere dettagli diversi nei vari reparti: i dettagli dell'ordine vengono acquisiti dalle vendite, la cronologia finanziaria viene acquisita dalla contabilità, mentre gli interessi dei clienti e l'attività online vengono acquisiti dal marketing. Il livello conformato crea una comprensione condivisa di tali dati in tutta l'organizzazione. Vantaggi inclusi:
- Definizione coerente e unificata delle entità principali in tutta l'organizzazione.
- Conformità alle normative sulla sicurezza e sulla privacy dei dati.
- Flessibilità che bilancia l'uniformità a livello aziendale con la personalizzazione specifica del dominio tramite modelli centralizzati e distribuiti.
Non viene utilizzato direttamente per la business intelligence operativa, ma supporta l'analisi esplorativa dei dati, la BI self-service e l'arricchimento dei dati specifici del dominio.
Livello arricchito
Questo livello trasforma i dati del livello precedente in set di dati denominati prodotti di dati, personalizzati per casi d'uso specifici. I prodotti di dati possono variare da dashboard operative utilizzate per il processo decisionale quotidiano a profili dettagliati dei clienti, arricchiti con consigli personalizzati o approfondimenti sulle migliori azioni successive. Sono ospitati in vari database o applicazioni scelti in base al caso d'uso specifico.
Le organizzazioni catalogano i prodotti di dati in sistemi centralizzati di gestione dei dati per renderli individuabili e accessibili da parte di altri team. Ciò riduce la ridondanza e garantisce che i dati arricchiti di alta qualità siano facilmente accessibili.
Quali sono i tipi di architetture di dati?
Esistono due diversi approcci al livello conformato che creano diversi tipi di architettura dei dati.
Architettura di dati centralizzata
Nelle architetture di dati centralizzate, il livello conformato si concentra sulla creazione e sulla gestione di entità comuni, come clienti o prodotti, che vengono utilizzate universalmente in tutta l'azienda. Le entità sono definite con un set limitato di attributi generici per una gestione più semplice dei dati e un'ampia applicabilità. Ad esempio, un'entità cliente potrebbe includere attributi principali come nome, età, professione e indirizzo.
Tali architetture di dati supportano la governance centralizzata dei dati, in particolare per informazioni sensibili come le informazioni di identificazione personale (PII) o le informazioni sulle carte di pagamento (PCI). La gestione centralizzata dei metadati garantisce che i dati siano catalogati e governati in modo efficace, con monitoraggio della derivazione e controlli del ciclo di vita per garantire trasparenza e sicurezza.
Tuttavia, questo modello evita di includere tutti gli attributi possibili, poiché la gestione centralizzata di requisiti di dati complessi rallenta il processo decisionale e l'innovazione. Invece, le proprietà specifiche del dominio, come le impressioni sulle campagne dei clienti (richieste solo dal marketing), vengono derivate nel livello arricchito dalle rispettive unità aziendali.
Le tecnologie data fabric sono utili per implementare architetture di dati centralizzate.
Architettura di dati distribuita
Ogni dominio crea e gestisce il proprio livello conformato nelle architetture di dati distribuite. Ad esempio, il marketing si concentra su attributi come segmenti di clienti, impressioni sulle campagne e conversioni, mentre la contabilità dà priorità a proprietà come ordini, ricavi e reddito netto.
Le architetture di dati distribuite consentono flessibilità nella definizione delle entità e delle loro proprietà, ma generano più set di dati per entità comuni. La rilevabilità e la governance di questi set di dati distribuiti sono ottenute tramite un catalogo centrale di metadati. Le parti interessate possono trovare e utilizzare il set di dati appropriato mentre supervisionano i processi di scambio dei dati.
Le tecnologie data mesh sono utili per implementare architetture di dati distribuite.
Che cos'è un framework di architettura dei dati?
Un framework di architettura dei dati è un approccio strutturato alla progettazione dell'architettura dei dati. Fornisce una serie di principi, standard, modelli e strumenti che garantiscono processi di gestione dei dati efficienti, in linea con gli obiettivi aziendali. Si può considerare come un blueprint standard che un architetto dei dati utilizza per creare architetture di dati complete e di alta qualità.
Alcuni esempi di framework di architettura dei dati includono
Il framework DAMA-DMBOK
Il framework Data Management Body of Knowledge (DAMA-DMBOK) delinea le best practice, i principi e i processi per una gestione efficace dei dati durante tutto il loro ciclo di vita. Supporta la definizione di pratiche coerenti di gestione dei dati, garantendo al contempo l'allineamento con gli obiettivi aziendali. Considerando le risorse di dati come una risorsa strategica, il framework DAMA-DMBOK fornisce indicazioni pratiche per migliorare il processo decisionale e l'efficienza operativa.
Il framework Zachman
Il framework Zachman è un framework di architettura aziendale che utilizza un formato a matrice per definire le relazioni tra diverse prospettive (come titolare d'azienda, progettista e builder) e sei interrogativi chiave (cosa, come, dove, chi, quando e perché). Le organizzazioni possono visualizzare in che modo i dati si adattano alle loro operazioni complessive, assicurandosi che i processi relativi ai dati siano in linea con gli obiettivi aziendali e i requisiti di sistema. Il framework Zachman è ampiamente riconosciuto per la sua capacità di chiarire le dipendenze dei dati e dei sistemi a livello aziendale.
TOGAF
L'Open Group Architecture Framework (TOGAF) considera l'architettura dei dati come una componente fondamentale di un sistema più ampio, enfatizzando la creazione di modelli di dati, flussi di dati e strutture di governance che supportino le esigenze organizzative. Stabilisce processi di dati standardizzati, garantendo l'interoperabilità del sistema e una gestione efficiente dei dati. È particolarmente vantaggioso per le grandi aziende che desiderano allineare le proprie strategie IT e aziendali attraverso un approccio unificato.
Come si confronta l'architettura dei dati con altri termini correlati?
Le diverse terminologie relative ai dati sembrano simili ma hanno significati completamente diversi. Di seguito forniamo alcune spiegazioni.
Architettura dei dati e architettura dell'informazione
L'architettura dell'informazione è l'organizzazione e la presentazione delle informazioni agli utenti finali. Il termine si applica alle interfacce utente, ai siti web o ai sistemi di contenuti e si riferisce all'accessibilità delle informazioni da parte degli utenti finali. I principi e gli strumenti dell'architettura dell'informazione si concentrano sulla navigazione, la categorizzazione e la ricercabilità, ad esempio all'interno di un knowledge store online o di un database di documenti.
L'architettura dei dati, invece, si concentra sulla progettazione e sulla gestione di tutti i dati organizzativi. Si occupa di tutta l'infrastruttura tecnica dei dati di backend, mentre l'architettura delle informazioni si concentra solo sul modo in cui gli utenti finali interagiscono con le informazioni e le interpretano.
Architettura dei dati e ingegneria dei dati
L'ingegneria dei dati è l'implementazione pratica dell'architettura dei dati. Gli architetti dei dati forniscono un piano generale per la gestione delle risorse di dati di un'organizzazione. Progettano sistemi di dati scalabili in linea con gli obiettivi aziendali e le policy di sicurezza. Gli ingegneri dei dati implementano il piano, creando, mantenendo e ottimizzando le pipeline di dati. Garantiscono che i dati vengano importati, puliti, trasformati e consegnati per l'analisi secondo le regole dell'architettura dei dati.
Architettura dei dati e modellazione dei dati
La modellazione dei dati è un processo all'interno dell'architettura dei dati che crea una rappresentazione visiva di qualsiasi raccolta di dati. Include la creazione di modelli di dati concettuali, logici e fisici che delineano i dati nella raccolta. Un modello logico di dati rappresenta schematicamente i vincoli dei dati, i nomi delle entità e le relazioni per l'implementazione in modo indipendente dalla piattaforma. Un modello di dati fisico perfeziona ulteriormente il modello logico per l'implementazione su una tecnologia di dati specifica.
L'architettura dei dati ha un ambito molto più ampio che va oltre la modellazione dei dati. Oltre agli attributi e alle relazioni dei dati, definisce anche una strategia più ampia per la gestione dei dati a livello di organizzazione. Include infrastruttura, policy e tecnologie per l'integrazione dei dati in linea con gli obiettivi organizzativi.
In che modo AWS può supportare i tuoi requisiti di architettura dei dati?
AWS fornisce un set completo di servizi di analisi per ogni livello dell'architettura dei dati, dall'archiviazione e gestione alla governance dei dati e all'intelligenza artificiale. AWS offre servizi personalizzati con il miglior rapporto tra prezzo e prestazioni, scalabilità e costi più bassi. Ad esempio,
- I database su AWS includono oltre 15 servizi di database dedicati per supportare diversi modelli di dati relazionali e non relazionali.
- I data lake su AWS includono servizi che forniscono un'archiviazione illimitata di dati non elaborati e che consentono di creare data lake sicuri in pochi giorni anziché in mesi.
- L'integrazione dei dati con AWS include servizi che riuniscono dati provenienti da più origini in modo da poter trasformare, rendere operativi e gestire i dati in tutta l'organizzazione.
AWS Well-Architected aiuta gli architetti dei dati del cloud a creare un'infrastruttura sicura, ad alte prestazioni, resiliente ed efficiente. Il Centro di architettura AWS include linee guida basate su casi d'uso per l'implementazione di varie architetture di dati moderne all'interno dell'organizzazione.
Inizia a usare l'architettura dei dati su AWS creando un account gratuito oggi stesso.
Fasi successive su AWS
Ottieni accesso istantaneo al piano gratuito di AWS.