- Analytik›
- Amazon EMR›
- Funktionen
Features von Amazon EMR
Einfache Nutzung
Übersicht
Amazon EMR vereinfacht das Erstellen und den Betrieb von Big-Data-Umgebungen und -Anwendungen. Zu den verwandten EMR-Features gehören die einfache Bereitstellung, die verwaltete Skalierung und Neukonfiguration von Clustern sowie EMR Studio für die gemeinsame Entwicklung.
Bereitstellung von Clustern in wenigen Minuten
Sie können ein EMR-Cluster in wenigen Minuten starten. Sie brauchen sich nicht um die Bereitstellung von Knoten, die Einrichtung, die Konfiguration oder die Optimierung von Clustern zu kümmern. EMR übernimmt diese Aufgaben und ermöglicht Ihnen, Ihre Teams auf die Entwicklung von unterschiedlichen Anwendungen für Big Data zu fokussieren.
Einfache Skalierung von Ressourcen, um die Geschäftsanforderungen zu erfüllen
Mithilfe von EMR Managed Scaling-Richtlinien können Sie die Skalierung und Skalierung einfach festlegen und Ihren EMR-Cluster die Rechenressourcen automatisch verwalten lassen, um Ihre Nutzungs- und Leistungsanforderungen zu erfüllen. Dies verbessert die Nutzung der Cluster und spart Kosten.
EMR Studio
Ist eine integrierte Entwicklungsumgebung (IDE), die es Datenwissenschaftlern und Dateningenieuren erleichtert, in R, Python, Scala und PySpark geschriebene Dateningenieurs- und Datenwissenschafts-Anwendungen zu entwickeln, zu visualisieren und zu debuggen. EMR Studio bietet vollständig verwaltete Jupyter Notebooks und Tools wie Spark UI und YARN Timeline Service, um das Debugging zu vereinfachen.
Hochverfügbarkeit mit nur einem Klick
Sie können die Hochverfügbarkeit für Multi-Master-Anwendungen wie YARN, HDFS, Apache Spark, Apache HBase und Apache Hive mit einem einzigen Klick einfach konfigurieren. Wenn Sie die Multi-Master-Unterstützung in EMR aktivieren, konfiguriert EMR diese Anwendungen für Hochverfügbarkeit und führt bei Fehlern automatisch ein Failover auf einen Standby-Master durch, damit Ihr Cluster nicht gestört wird, und platziert Ihre Master-Knoten an anderen Racks, um das Risiko eines gleichzeitigen Ausfalls zu verringern. Hosts werden überwacht, um Fehler zu entdecken und wenn Probleme entdeckt werden, werden neue Hosts bereitgestellt und zum Cluster automatisch hinzugefügt.
EMR Managed Scaling
Ändert die Größe Ihres Clusters automatisch, um die beste Leistung zu möglichst geringen Kosten zu erzielen. Mit EMR Managed Scaling legen Sie die minimalen und maximalen Rechengrenzen für Ihre Cluster fest, und Amazon EMR ändert die Größe automatisch, um die beste Leistung und Ressourcennutzung zu erzielen. EMR Managed Scaling untersucht kontinuierlich wichtige Metriken, die mit den auf Clustern ausgeführten Workloads verknüpft sind.
Einfache Neukonfiguration laufender Cluster
Sie können jetzt die Konfiguration von Anwendungen ändern, die in EMR-Clustern wie Apache Hadoop, Apache Spark, Apache Hive und Hue ausgeführt werden, ohne den Cluster neu zu starten. Die Neukonfiguration von EMR-Anwendungen ermöglicht Ihnen, Anwendungen spontan zu verändern, ohne den Cluster herunterfahren oder wiederherstellen zu müssen. Amazon EMR wendet Ihre neuen Konfigurationen an und startet die rekonfigurierte Anwendung elegant neu. Konfigurationen können über die Konsole, SDK oder CLI angewandt werden.
Elastic
Übersicht
Mit Amazon EMR können Sie schnell und einfach automatisch oder manuell Kapazität in beliebigem Umfang hinzufügen oder entfernen. Das ist sehr nützlich bei variablen oder nicht vorhersagbaren Verarbeitungsanforderungen. So kann es bei einem Verarbeitungsschwerpunkt in der Nacht sein, dass Sie tagsüber 100 Instances, in der Nacht aber 500 Instances benötigen. Oder es tritt der Fall ein, dass Sie für einen kurzen Zeitraum erhebliche Kapazitäten benötigen. Mit Amazon EMR können Sie kurzfristig Hunderte und Tausende von Instances bereitstellen, automatisch entsprechend den Rechenanforderungen skalieren und die Cluster herunterfahren, sobald die Aufgabe erledigt ist (um nicht für ungenutzte Kapazität zu zahlen).

Es gibt zwei Hauptoptionen für das Hinzufügen und Entfernen von Kapazitäten:
Mehrere Cluster bereitstellen
Wenn Sie mehr Kapazität benötigen, können Sie einfach einen neuen Cluster starten, den Sie wieder beenden, sobald Sie ihn nicht mehr benötigen. Sie können unbeschränkt viele Cluster haben. Bei mehreren Benutzern oder Anwendungen kann es ratsam sein, mehrere Cluster zu verwenden. So können Sie beispielsweise Ihre Eingabedaten in Amazon S3 speichern und für jede Anwendung, die diese Daten verarbeiten muss, einen eigenen Cluster starten. Ein Cluster kann für die CPU optimiert sein, ein anderer für die Speicherung usw.
Größe eines ausgeführten Clusters ändern
Mit Amazon EMR können Sie unter Verwendung von EMR Managed Scaling die Größe eines ausgeführten Clusters auf einfache Weise automatisch skalieren oder manuell ändern. Vergrößern Sie ein Cluster beispielsweise vorübergehend, um die Verarbeitungsleistung zu erhöhen, oder verkleinern Sie es, um Kosten zu sparen, wenn Sie die Kapazität nicht benötigen. Manche Kunden fügen bei Stapelverarbeitung Hunderte Instances hinzu, die sie danach wieder entfernen. Wenn Sie Ihrem Cluster Instances hinzufügen, kann EMR jetzt die bereitgestellte Kapazität unmittelbar nutzen. Beim Skalieren wählt EMR proaktiv Knoten im Leerlauf aus, um die Auswirkungen auf aktive Aufträge zu reduzieren.
Geringe Kosten
Übersicht
Amazon EMR ist für Kostenreduktion bei der Verarbeitung großer Datenmengen konzipiert. Dafür sorgen Merkmale wie die günstige sekundenbasierte Verrechnung, die Amazon EC2 Spot-Integration, die Amazon EC2 Reserved Instance-Integration, die Elastizität und die Amazon S3-Integration.
Günstige Sekundensätze
Amazon EMR wird pro Sekunde mit einem Minimum von einer Minute in Rechnung gestellt, beginnend bei 0,015 USD pro Instance-Stunde für kleine Instances (131,40 USD pro Jahr). Im Abschnitt Preise finden Sie weitere Details.
Amazon EC2-Spot-Integration
Der Preis für Amazon EC2-Spot-Instances schwankt abhängig von Angebot und Nachfrage an Instances, doch Sie zahlen niemals mehr als den von Ihnen angegebenen Höchstpreis. Mit Amazon EMR ist die Nutzung von Spot Instances einfach – so sparen Sie Zeit und Geld. Amazon EMR-Cluster haben ‚Kernknoten‘, auf denen HDFS läuft, und ‚Aufgabenknoten‘, bei denen das nicht der Fall ist. Aufgabenknoten sind ideal für Spot, denn wenn der Spot-Preis steigt und Sie diese Instances verlieren, verlieren Sie keine in HDFS gespeicherten Daten. (Weitere Informationen zu Kern- und Aufgabenknoten). Mit der Kombination aus Instance-Flotten, Zuordnungsstrategien für Spot-Instances, EMR Managed Scaling und mehr Diversifizierungsoptionen können Sie EMR jetzt hinsichtlich Ausfallsicherheit und Kosten optimieren. Mehr erfahren Sie in unserem Blog.
Amazon-S3-Integration
Das EMR File System (EMRFS) ermöglicht EMR-Clustern die effiziente und sichere Verwendung von Amazon S3 als Objektspeicher für Hadoop. Sie können Ihre Daten in Amazon S3 speichern und mehrere Amazon EMR-Cluster zum Verarbeiten derselben Datenmenge verwenden. Jeder Cluster kann für eine bestimmte Verarbeitungslast optimiert werden. Das ist oft effizienter als ein einzelner Cluster, der verschiedene Verarbeitungslasten mit unterschiedlichen Anforderungen bedient. So können Sie etwa einen Cluster haben, der für E/A optimiert ist, und einen anderen für CPU, wobei beide denselben Datensatz in Amazon S3 verarbeiten. Außerdem können Sie, wenn Sie Ihre Eingabe- und Ausgabedaten in Amazon S3 speichern, Cluster herunterfahren, wenn sie nicht weiter benötigt werden.
EMRFS ist leistungsstark beim Lesen von und Schreiben auf Amazon S3, unterstützt serverseitige oder clientseitige S3-Verschlüsselung mithilfe von AWS Key Management Service (KMS) oder vom Kunden verwalteten Schlüsseln und bietet eine optionale konsistente Ansicht, die auf Listen- und Lesen-nach-Schreiben-Konsistenz für Objekte prüft, die in den Metadaten nachverfolgt werden. Außerdem können Amazon EMR-Cluster sowohl EMRFS als auch HDFS benutzen, sodass Sie sich nicht zwischen On-Cluster-Speicherung und Amazon S3 zu entscheiden brauchen.
Integration des AWS Glue-Datenkatalogs
Sie können den AWS Glue-Datenkatalog als verwaltetes Metadaten-Repository nutzen, um externe Tabellenmetadaten für Apache Spark und Apache Hive zu speichern. Der Datenkatalog bietet zudem eine automatische Schemaerkennung und zeichnet den Verlauf der Schemaversionen auf. Dies ermöglicht es Ihnen, Metadaten für Ihre externen Tabellen in Amazon S3 auf einfache Weise dauerhaft außerhalb Ihres Clusters zu speichern.
Flexible Datenspeicher
Übersicht
Mit Amazon EMR können Sie mehrere Datenspeicher nutzen, einschließlich Amazon S3, das Hadoop Distributed File System (HDFS) und Amazon DynamoDB.
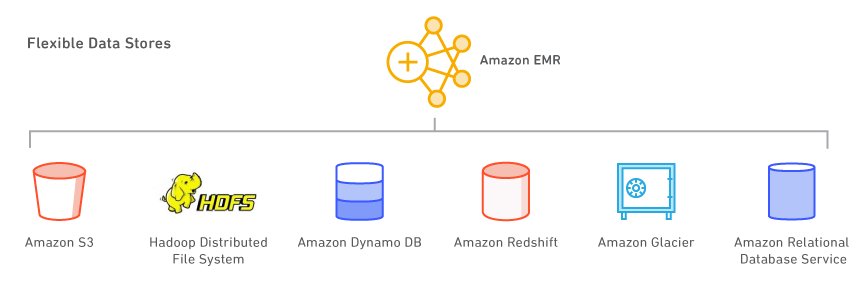
Amazon S3
Amazon S3 ist der überaus zuverlässige, skalierbare, sichere, schnelle und kostengünstige Speicherservice von Amazon. Mit dem EMR File System (EMRFS) kann Amazon EMR Amazon S3 effizient und sicher als Objektspeicher für Hadoop nutzen. Amazon EMR hat Hadoop in mehreren Hinsichten verbessert, damit Sie problemlos große in Amazon S3 gespeicherte Datenmengen verarbeiten können. EMRFS kann auch eine konsistente Ansicht aktivieren, um Objekte in Amazon S3 auf Listen- und Lesen-nach-Schreiben-Konsistenz zu prüfen. EMRFS unterstützt serverseitige oder clientseitige S3-Verschlüsselung, um verschlüsselte Amazon S3-Objekte zu verarbeiten. Sie können auch den AWS Key Management Service (KMS) oder einen benutzerdefinierten Schlüsselanbieter verwenden.
Wenn Sie einen Cluster starten, streamt Amazon EMR die Daten von Amazon S3 zu jeder Instance Ihres Clusters und beginnt sofort mit der Verarbeitung. Die Speicherung der Daten in Amazon S3 und deren Verarbeitung in Amazon EMR hat unter anderem den Vorteil, dass Sie mehrere Cluster zur Verarbeitung derselben Daten einsetzen können. Sie könnten beispielsweise über einen Hive-Entwicklungs-Cluster verfügen, der für Arbeitsspeicher optimiert ist, und einen Pig-Produktions-Cluster, der für CPU optimiert ist, wobei beide die gleiche Eingabedatenmenge verwenden.
Hadoop Distributed File System (HDFS)
HDFS ist das Hadoop-Dateisystem. Mit der aktuellen Amazon EMR-Topologie werden Instances in drei logische Instance-Gruppen unterteilt: die Master-Gruppe, die den YARN Resource Manager- und den HDFS Name Node Service ausführt, die Kerngruppe, die den HDFS DataNode Daemon und den YARN Node Manager Service ausführt, und die Aufgabengruppe, die den YARN Node Manager Service ausführt. Amazon EMR installiert HDFS in dem mit den Instances in der Kerngruppe verknüpften Speicher.
Jede EC2-Instance verfügt über eine feste Speichermenge, die als "Instance-Speicher" bezeichnet wird und mit der Instance verbunden ist. Sie können den Speicher einer Instance auch anpassen, indem Sie der Instance Amazon EBS-Volumes hinzufügen. Sie können mit Amazon EMR standardmäßige (SSD), bereitgestellte (SSD) und magnetische Volume-Typen hinzufügen. Die einem EMR-Cluster hinzugefügten EBS-Volumes behalten Daten nach dem Herunterfahren des Clusters nicht bei. EMR bereinigt die Volumes automatisch, sobald Sie den Cluster beenden.
Sie können auch die vollständige Verschlüsselung für HDFS mithilfe einer Amazon EMR-Sicherheitskonfiguration aktivieren oder HDFS-Verschlüsselungszonen mit dem Hadoop Key Management Server manuell erstellen. Sie können eine Sicherheitskonfigurationsoption verwenden, um EBS-Root-Geräte und Speichervolumes zu verschlüsseln, wenn Sie AWS KMS als Ihren Schlüsselanbieter angeben. Weitere Informationen finden Sie unter Lokale Festplattenverschlüsselung.
Amazon DynamoDB
Amazon DynamoDB ist ein vollständig verwalteter NoSQL-Datenbankservice. Amazon EMR ist direkt mit Amazon DynamoDB integriert, sodass Sie hier schnell und effizient in Amazon DynamoDB gespeicherte Daten verarbeiten und Daten zwischen Amazon DynamoDB, Amazon S3 und HDFS in Amazon EMR übertragen können.
Andere AWS-Datenspeicher
Sie können auch den Amazon Relational Database Service (einen Webservice, mit dem sich relationale Datenbanken in der Cloud problemlos einrichten, betreiben und skalieren lassen), Amazon Glacier (einen besonders kostengünstigen Speicherservice zum Archivieren und Sichern von Daten) und Amazon Redshift (einen schnellen, vollständig verwalteten Data Warehouse-Service im Petabyte-Bereich) nutzen. AWS Data Pipeline ist ein Webservice zur Unterstützung des zuverlässigen Verarbeitens und Verschiebens von Daten zwischen AWS-Datenverarbeitungs- und -Speicherservices (einschließlich Amazon EMR) sowie lokalen Datenquellen in angegebenen Intervallen.
Nutzen Sie Ihre bevorzugten Open-Source-Anwendungen
Übersicht
Dank Versionsverwaltung auf Amazon EMR können Sie problemlos die neuesten Open-Source-Projekte auf Ihrem EMR-Cluster öffnen, darunter auch Anwendungen in den Ökosystemen von Apache Spark und Hadoop. Die Software wird von Amazon EMR installiert und konfiguriert. Ihnen bleibt dadurch mehr Zeit zur Steigerung der Wertschöpfung Ihrer Daten, ohne sich Gedanken über die Infrastruktur oder Verwaltungsaufgaben machen zu müssen.

Big Data-Tools
Übersicht
Amazon EMR unterstützt leistungsstarke und bewährte Hadoop-Tools wie Apache Spark, Apache Hive, Presto und Apache HBase. Datenwissenschaftler verwenden EMR und Deep-Learning- und Machine-Learning-Tools wie TensorFlow, Apache MXNet, um mithilfe von Bootstrap-Aktionen eigene Tools und Bibliotheken für den jeweiligen Anwendungsfall hinzuzufügen. Datenanalysten verwenden für die interaktive Entwicklung EMR Studio, Hue und EMR Notebooks, um Apache Spark-Aufgaben zu erstellen und SQL-Abfragen an Apache Hive und Presto zu senden. Dateningenieure nutzen EMR für die Datenpipelineentwicklung und Datenverarbeitung und Apache Hudi, um verstärktes Datenmanagement und Datenprivatssphäre zu vereinfachen, die Einlagen, Aktualisierungen und Löschvorgänge auf Rekordniveau benötigen.

Datenverarbeitung und Machine Learning
Apache Spark ist eine Engine im Hadoop-Ökosystem für rasche Verarbeitung großer Datenmengen. Es verwendet zur Definition von Datentransformationen fehlertolerante In-Memory-RDDs (Resilient Distributed Datasets – ausfallsichere verteilte Datenmengen) und DAGs (Directed, Acyclic Graphs – gerichtete, azyklische Graphen). Spark umfasst auch Spark SQL, Spark Streaming, MLlib und GraphX. Weitere Informationen zu Spark und Spark auf Amazon EMR.
Apache Flink ist eine Streaming-Datenfluss-Engine, die mittels Datenquellen mit hohem Durchsatz die Echtzeitverarbeitung von Streams ermöglicht. Sie unterstützt Zeitsemantik für Ausfallereignisse, Semantik für genau einmal auftretende Ereignisse, Rückdrucksteuerung und APIs, die für das Erstellen von Streaming- und Batch-Anwendungen optimiert wurden. Weitere Informationen zu Flink und Flink auf EMR.
TensorFlow ist eine Open-Source-Bibliothek für symbolische Mathematik für maschinelle Intelligenz und Deep-Learning-Anwendungen. TensorFlow bündelt mehrere Modelle und Algorithmen für maschinelles Lernen und Deep Learning und kann tiefe neuronale Netze für viele verschiedene Anwendungsfälle trainieren und ausführen. Weitere Informationen zu TensorFlow bei EMR .
Amazon S3 Datenmanagement auf Rekordniveau
Apache Hudi ist ein Open-Source-basiertes Datenmanagement-Framework zur Vereinfachung der inkrementellen Datenverarbeitung und der Entwicklung von Datenpipelines. Apache Hudi ermöglicht die Verwaltung von Daten auf Rekordniveau in Amazon S3, um Change Data Capture (CDC) und Streaming Data Ingestion zu vereinfachen, und es bietet einen Rahmen, um Datenprivatsphäre, die Rekordniveau-Aktualisierungen und Löschvorgänge erfordern, zu bearbeiten. Hier erhalten Sie weitere Informationen zu Apache Hudi auf Amazon EMR.
SQL
Apache Hive ist ein Open-Source-Data-Warehouse und Analysepaket, das auf Hadoop ausgeführt wird. Hive wird mit Hive QL betrieben, einer SQL-basierten Sprache, mit der die Benutzer Daten strukturieren, zusammenfassen und abfragen können. Hive QL geht über Standard-SQL hinaus: Es wird ein erstklassiger Support für "Map"- und "Reduce"-Funktionen sowie komplexe erweiterbare, benutzerdefinierte Datentypen wie Json und Thrift angeboten. Damit wird die Verarbeitung komplexer und unstrukturierter Datenquellen ermöglicht, etwa von Textdokumenten und Protokolldateien. In Hive sind mittels in Java geschriebener benutzerdefinierter Funktionen anwenderspezifische Erweiterungen möglich. Amazon EMR hat zahlreiche Verbesserungen an Hive vorgenommen, etwa eine direkte Integration mit Amazon DynamoDB und Amazon S3 geschaffen. Beispiel: Sie können in Amazon EMR Tabellenpartitionen automatisch aus Amazon S3 laden, Sie können in Amazon S3 Daten ohne den Umweg über temporäre Dateien in Tabellen schreiben, Sie können in Amazon S3 auf Ressourcen wie Scripts für benutzerdefinierte map/reduce-Operationen und zusätzliche Bibliotheken zugreifen. Weitere Informationen zu Hive und Hive auf EMR.
Presto ist eine verteilte Open-Source-SQL-Abfrage-Engine, optimiert für Ad-hoc-Datenanalysen mit geringer Latenz. Sie unterstützt den ANSI-SQL-Standard, einschließlich komplexer Abfragen, Aggregationen, Verknüpfungen und Fensterfunktionen. Presto kann Daten aus mehreren Datenquellen verarbeiten, etwa Hadoop Distributed File System (HDFS) und Amazon S3. Weitere Informationen zu Presto und Presto auf EMR.
Apache Phoenix ermöglicht SQL mit niedriger Latenz und ACID-Transaktionsfunktionen für in Apache HBase gespeicherte Daten. Sie können problemlos sekundäre Indizes für zusätzliche Leistung und verschiedene Sichten der gleichen zugrunde liegenden HBase-Tabelle erstellen. Weitere Informationen zu Phoenix auf EMR.
NoSQL
Apache HBase ist eine nicht relationale, verteilte Open-Source-Datenbank nach dem Vorbild von Google BigTable. Sie wurde im Rahmen des Hadoop-Projekts der Apache Software Foundation entwickelt und wird auf Hadoop Distributed File System (HDFS) ausgeführt, um für Hadoop Kapazitäten wie bei BigTable bereitzustellen. HBase bietet eine fehlertolerante, effiziente Methode für die Speicherung großer Mengen von Daten mit geringer Dichte. Es setzt dazu spaltenbasierte Kompression und Speicherung ein. Außerdem stellt HBase eine schnelle Datensuche bereit, da es Daten im Arbeitsspeicher zwischenspeichert. HBase ist für serielle Schreiboperationen optimiert und besonders effizient für Batch-Inserts, Updates und Löschvorgänge. HBase arbeitet problemlos mit Hadoop, verwendet dasselbe Dateisystem und dient als Direkt-Ein- und -Ausgabe für Hadoop-Aufträge. HBase lässt sich auch mit Apache Hive integrieren, ermöglicht SQL-artige Abfragen von HBase-Tabellen und Join-Vorgänge mit Hive-basierten Tabellen und unterstützt Java Database Connectivity (JDBC). Mit EMR können Sie S3 als Datenspeicher für Apache HBase verwenden, sodass Sie die Kosten senken und die Betriebskomplexität reduzieren können. Wenn Sie HDFS als Datenspeicher verwenden, können Sie HBase in S3 sichern und aus einer zuvor erstellten Sicherung wiederherstellen. Erfahren Sie, was HBase ist und mehr über HBase auf EMR.
Interaktive Analysen
EMR Studio ist eine integrierte Entwicklungsumgebung (IDE), die es Datenwissenschaftlern und Dateningenieuren erleichtert, in R, Python, Scala und PySpark geschriebene Dateningenieurs- und Datenwissenschafts-Anwendungen zu entwickeln, zu visualisieren und zu debuggen. EMR Studio bietet vollständig verwaltete Jupyter Notebooks und Tools wie Spark UI und YARN Timeline Service, um das Debugging zu vereinfachen.
Hue ist eine Open Source-Schnittstelle für Hadoop, die das Ausführen und Entwickeln von Hive-Abfragen, die Dateiverwaltung in HDFS, das Ausführen und Entwickeln von P-Scripts und die Tabellenverwaltung vereinfacht. Hue auf EMR bietet auch eine Integration mit Amazon S3, Sie können also direkt für S3 abfragen und Dateien problemlos zwischen HDFS und Amazon S3 übertragen. Weitere Informationen zu HUE und EMR.
Jupyter Notebook ist eine Open-Source-Webanwendung, mit der Sie Dokumente erstellen und freigeben können, die Live-Code, Gleichungen, Visualisierungen und narrativen Text enthalten. Mit JupyterHub können Sie mehrere Instanzen eines Einzelbenutzer-Jupyter-Notebook-Servers hosten. Wenn Sie mit JupyterHub einen EMR-Cluster erstellen, erstellt EMR einen Docker-Container auf dem Masterknoten des Clusters. JupyterHub, alle für Jupyter erforderlichen Komponenten und Sparkmagic werden im Container ausgeführt.
Apache Zeppelin ist eine Open-Source-GUI, die interaktive Notizbücher für die Zusammenarbeit bei der Datenuntersuchung mithilfe von Spark erstellt. Sie können Scala, Python, SQL (mit Spark SQL) oder HiveQL verwenden, um Daten zu bearbeiten und Ergebnisse schnell zu visualisieren. Zeppelin-Notizbücher können von mehreren Benutzern gemeinsam genutzt werden und Visualisierungen können in externen Dashboards veröffentlicht werden. Weitere Informationen zu Zeppelin auf EMR.
Terminplanung und Workflow
Apache Oozie ist ein Workflow-Zeitplaner für Hadoop, in dem Sie Directed Acyclic Graphs (DAGs) von Aktionen erstellen können. Sie können Ihre Hadoop-Workflows auch einfach durch Aktionen oder zu einer bestimmten Uhrzeit auslösen. Weitere Informationen zur Oozie auf EMR. AWS Step Functions ermöglicht Ihnen, Ihren Anwendungen eine resiliente Workflow-Automatisierung hinzuzufügen. Die Schritte Ihres Workflows können überall ausgeführt werden, darunter in AWS Lambda-Funktionen, auf Amazon Elastic Compute Cloud (EC2) oder vor Ort. Weitere Informationen zu Step Functions auf EMR.
Andere Projekte und Tools
EMR unterstützt auch eine Vielzahl anderer beliebter Anwendungen und Tools wie R, Apache Pig (Datenverarbeitung und ETL), Apache Tez (komplexe DAG-Ausführung), Apache MXNet (vertieftes Lernen), Ganglia (Überwachung), Apache Sqoop (Konnektor für relationale Datenbanken), HCatalog (Tabellen- und Speicherverwaltung) und vieles mehr. Das Amazon EMR-Team unterhält ein Open Source-Repository von Bootstrap-Aktionen, das zur Installation zusätzlicher Software und zum Konfigurieren Ihres Clusters verwendet werden kann oder Ihnen Beispiele für das Schreiben Ihrer eigenen Bootstrap-Aktionen an die Hand gibt.
Datenzugriffskontrolle
Übersicht
Amazon EMR-Anwendungsprozesse verwenden standardmäßig EC2-Instance-Profile, wenn sie andere AWS-Services abrufen. Bei Multi-Tenant-Clustern bietet Amazon EMR drei Optionen zum Verwalten des Benutzerzugriffs auf Amazon-S3-Daten.
Integration mit AWS Lake Formation ermöglicht es Ihnen, differenzierte Autorisierungsrichtlinien in AWS Lake Formation zu definieren und zu verwalten, um auf Datenbanken, Tabellen und Spalten im AWS-Glue-Datenkatalog zuzugreifen. Sie können die Autorisierungsrichtlinien bei Aufgaben durchsetzen, die über Amazon-EMR-Notebooks und Apache Zeppelin für interaktive EMR-Spark-Workloads eingereicht wurden, und Prüfungs-Ereignisse an AWS CloudTrail senden. Wenn Sie diese Integration aktivieren, aktivieren Sie auch Federated Single Sign-On für EMR Notebooks oder Apache Zeppelin von Enterprise-Identitätssystemen, die mit Security Assertion Markup Language (SAML) 2.0 kompatibel sind.
Die native Integration mit Apache Ranger ermöglicht es Ihnen, einen neuen oder bestehenden Apache-Ranger-Server einzurichten, um differenzierte Autorisierungsrichtlinien für Benutzer zum Zugriff auf Datenbanken, Tabellen und Spalten von Amazo- S3-Daten per Hive Metastore zu definieren und zu verwalten. Apache Ranger ist ein Open-Source-Tool zur Aktivierung, Überwachung und Verwaltung umfassender Datensicherheit auf der Hadoop-Plattform.
Diese native Integration ermöglicht es Ihnen, drei Arten von Autorisierungsrichtlinien auf dem Apache-Ranger-Policy-Admin-Server zu definieren. Sie können die Autorisierung auf Tabellen-, Spalten- und Zeilenebene für Hive, die Autorisierung auf Tabellen- und Spaltenebene für Spark und die Autorisierung auf Präfix- und Objektebene für Amazon S3 festlegen. Amazon EMR installiert und konfiguriert automatisch die entsprechenden Apache Ranger-Plugins auf dem Cluster. Diese Ranger-Plugins synchronisieren sich mit dem Policy-Admin-Server für Autorisierungsrichtlinien, setzen die Datenzugriffskontrolle durch und senden Prüfereignisse an Amazon CloudWatch Logs.
Amazon EMR User Role Mapper ermöglicht es Ihnen, AWS-IAM-Berechtigungen zum Verwalten des Zugriffs auf AWS-Ressourcen zu nutzen. Sie können Zuordnungen zwischen Benutzern (oder Gruppen) und benutzerdefinierten IAM-Rollen erstellen. Ein Benutzer oder eine Gruppe kann nur auf die Daten zugreifen, wenn es die benutzerdefinierte IAM-Rolle erlaubt. Dieses Feature ist derzeit über AWS-Labs verfügbar.
Konsistente Hybrid-Erfahrung
Übersicht
AWS Outposts ist ein vollständig verwalteter Service, der die AWS-Infrastruktur, AWS-Services, APIs und Tools in praktisch jedem Rechenzentrum, jedem Co-Location-Bereich und jeder On-Premises-Einrichtung erweitert und eine wahrhaft konsistente Hybrid-Erfahrung bereitstellt. Mit Amazon EMR in AWS Outposts können Sie EMR-Cluster in Ihrem Rechenzentrum mithilfe derselben für EMR verwendeten AWS-Managementkonsole, SDK (Software Development Kit) und Befehlszeilenschnittstelle (Command Line Interface, CLI) bereitstellen und verwalten.
Weitere Funktionen
Wählen Sie die richtige Instance für Ihren Cluster
Auf Basis der Anforderungen Ihrer Anwendung legen Sie fest, welche EC2-Instance-Typen in Ihrem Cluster bereitgestellt werden (Standard, High Memory, High CPU, High I/O usw.). Sie haben bei jeder Instance Root-Zugriff und können Ihren Cluster vollständig an Ihre Anforderungen anpassen. Weitere Informationen zu unterstützten Amazon EC2-Instance-Typen. Amazon EMR bietet jetzt bis zu 30 % niedrigere Kosten und bis zu 15 % verbesserte Leistung für Spark-Workloads auf Graviton2-basierten Instances. Erfahren Sie mehr aus unserem Blog.
Steuern Sie den Netzwerkzugriff auf Ihren Cluster
Sie können Ihren Cluster in Amazon Virtual Private Cloud (VPC), einem logisch isolierten Abschnitt der AWS-Cloud, in Betrieb nehmen. Sie haben die vollständige Kontrolle über Ihre virtuelle Netzwerkumgebung, u. a. bei der Auswahl Ihres eigenen IP-Adressbereichs, dem Erstellen von Subnetzen und der Konfiguration von Routing-Tabellen und Netzwerk-Gateways. Weitere Informationen zu Amazon EMR und Amazon VPC.
Debuggen Sie Ihre Anwendungen
Wenn Sie in einem Cluster Debugging aktivieren, archiviert Amazon EMR die Protokolldateien auf Amazon S3 und indiziert diese Dateien. Sie können dann die grafische Oberfläche in der Konsole verwenden, um die Protokolle zu durchsuchen und den Auftragsverlauf auf intuitive Weise anzuzeigen. Weitere Informationen zum Debuggen von Amazon EMR-Aufträgen.
Benutzer, Berechtigungen und Verschlüsselung verwalten
Sie können mithilfe von AWS Identity and Access Management-Tools (IAM) den Zugriff und die Berechtigungen regeln, etwa mit IAM-Benutzern und -Rollen. So können Sie bestimmten Benutzern Lese-, aber keinen Schreibzugriff auf Ihre Cluster gewähren. Darüber hinaus können Sie Amazon EMR-Sicherheitskonfigurationen verwenden, um verschiedene Verschlüsselungsoptionen für Daten im Ruhezustand und während der Übertragung festzulegen, darunter auch Unterstützung für die Amazon S3-Verschlüsselung und die Kerberos-Authentifizierung. Weitere Informationen zur Steuerung des Clusterzugriffs und Amazon EMR-Verschlüsselungsoptionen.
Überwachen Sie Ihren Cluster
Sie können mit Amazon CloudWatch benutzerdefinierte Amazon EMR-Metriken überwachen, etwa die durchschnittliche Anzahl der Map- und Reduce-Aufgaben. Sie können auch Alarme für diese Metriken einstellen. Weitere Informationen zur Überwachung von Amazon EMR-Clustern.
Installieren Sie zusätzliche Software
Installieren Sie mithilfe von Bootstrap-Aktionen oder einem benutzerdefinierten, unter Amazon Linux ausgeführten Amazon Machine Image (AMI) zusätzliche Software in Ihrem Cluster. Bootstrap-Aktionen sind Scripts, die auf Cluster-Knoten ausgeführt werden, wenn Amazon EMR den Cluster startet. Sie laufen, bevor Hadoop startet und der Knoten mit der Datenverarbeitung beginnt. Sie können Software auch vorab auf eine benutzerdefinierte Amazon Linux AMI laden und dort verwenden. Weitere Informationen zu Amazon EMR Bootstrap-Aktionen und benutzerdefinierten Amazon Linux AMIs.
Reagieren Sie auf Ereignisse
Sie können Amazon EMR-Ereignistypen in Amazon CloudWatch Events verwenden, um auf Statusänderungen in Ihren Amazon EMR-Clustern zu reagieren. Mithilfe einfacher Regeln, die Sie schnell einrichten können, können Sie Ereignisse anpassen und diese zu Amazon SNS-Themen, AWS Lambda-Funktionen, Amazon SQS-Warteschlangen und mehr weiterleiten. Weitere Informationen zu Ereignissen in Amazon EMR-Clustern.
Kopieren Sie Daten effizient
Mithilfe von S3DistCp, einer Amazon EMR-Erweiterung des Open-Source-Tools Distcp, die MapReduce zum effizienten Verschieben großer Datenmengen nutzt, können Sie schnell große Datenmengen von Amazon S3 in HDFS, von HDFS in Amazon S3 und zwischen Amazon S3-Buckets verschieben. Weitere Informationen zu S3DistCp.
Planen Sie sich wiederholende Workflows
Sie können AWS Data Pipeline zum Planen sich wiederholender Workflows mit Amazon EMR einsetzen. AWS Data Pipeline ist ein Webservice zur Unterstützung des zuverlässigen Verarbeitens und Verschiebens von Daten zwischen AWS-Datenverarbeitungs- und -Speicherservices sowie lokalen Datenquellen in angegebenen Intervallen. Weitere Informationen zu Amazon EMR und AWS Data Pipeline.
Custom JAR
Schreiben Sie ein Java-Programm, kompilieren Sie es mit der Hadoop-Version, die Sie verwenden möchten, und laden Sie es in Amazon S3 hoch. Dann können Sie über die Hadoop JobClient-Schnittstelle dem Cluster Hadoop-Aufträge übermitteln. Weitere Informationen zum Verarbeiten eines benutzerdefinierten JAR mit Amazon EMR.
Deep Learning
Verwenden Sie beliebte Rahmenwerke für das Deep Learning wie Apache MXNet zum Definieren, Schulen und Bereitstellen tiefgründiger neuraler Netzwerke. Sie können diese Rahmenbedingungen in Amazon EMR-Clustern mit GPU-Instances verwenden. Weitere Informationen zu MXNet auf Amazon EMR.