什么是 SageMaker 模型训练?
Amazon SageMaker Model Training 可减少大规模训练和调整机器学习 (ML) 模型的时间和成本,而无需管理基础架构。您可以充分利用目前可用的性能最高的机器学习计算基础设施,Amazon SageMaker AI 可自动扩展或缩减基础设施,从一个 GPU 扩展到数千个 GPU。为了更快地训练深度学习模型,SageMaker AI 可帮助您实时选择和优化数据集。SageMaker 分布式训练库可自动在 AWS GPU 实例之间拆分大型模型和训练数据集,或者您也可以使用第三方库,例如 DeepSpeed、Horovod 或 Megatron。通过自动监控和修复训练集群,在不中断的情况下对基础模型(FM)进行数周甚至数月的训练。
经济高效培训的优势
大规模训练模型
完全托管式训练作业
SageMaker 训练作业为大型分布式 FM 训练提供了完全托管式用户体验,消除了基础设施管理方面无差别的繁重工作。SageMaker 训练作业会自动启动一个有弹性的分布式训练集群,监控基础设施并自动从故障中恢复,以确保顺畅的训练体验。训练完成后,SageMaker 将关闭集群,您需要按净训练时间付费。此外,借助 SageMaker 训练作业,您可以灵活地选择最适合单个工作负载的正确实例类型(例如,在 P5 集群上预训练 LLM 或在 p4d 实例上微调开源 LLM),进一步节省训练预算。此外,SagerMaker 训练作业还为具有不同技术专业知识水平和不同工作负载类型的 ML 团队提供一致的用户体验。
SageMaker HyperPod
Amazon SageMaker HyperPod 是一种专用基础设施,可有效管理计算集群来扩展基础模型(FM)开发。它支持先进的模型训练技术、基础设施控制、性能优化和增强的模型可观测性。SageMaker HyperPod 预先配置了 SageMaker 分布式训练库,使您能够在 AWS 集群实例之间自动拆分模型和训练数据集,以帮助有效利用集群的计算和网络基础设施。它通过自动检测、诊断和恢复硬件故障来实现更具弹性的环境,使您能够连续数月不间断地训练 FM,从而将训练时间缩短多达 40%。
高性能分布式训练
SageMaker AI 通过在 AWS 加速器中自动拆分模型和训练数据集,可以更快地执行分布式训练。 其可帮助您优化 AWS 网络基础设施和集群拓扑的训练任务。该服务还优化了储存检查点的频率,以便通过配方来简化模型检查点,从而确保训练期间的开销最小。配方可帮助各种技能水平的数据科学家和开发人员从最先进的性能中获益,同时可以快速开始训练和微调公开可用的生成式人工智能模型,包括 Llama 3.1 405B、Mixtral 8x22B 和 Mistral 7B。配方包含一个已经过 AWS 测试的训练堆栈,从而避免了花费数周时间来测试不同模型配置的繁琐工作。您可以通过单行配方更改在基于 GPU 的实例和基于 AWS Trainium 的实例之间切换,并启用自动模型检查点来提高训练弹性。此外,您可以在自己选择的 SageMaker 训练功能上将工作负载投入生产环境中运行。
内置工具可实现最高精度和最低成本
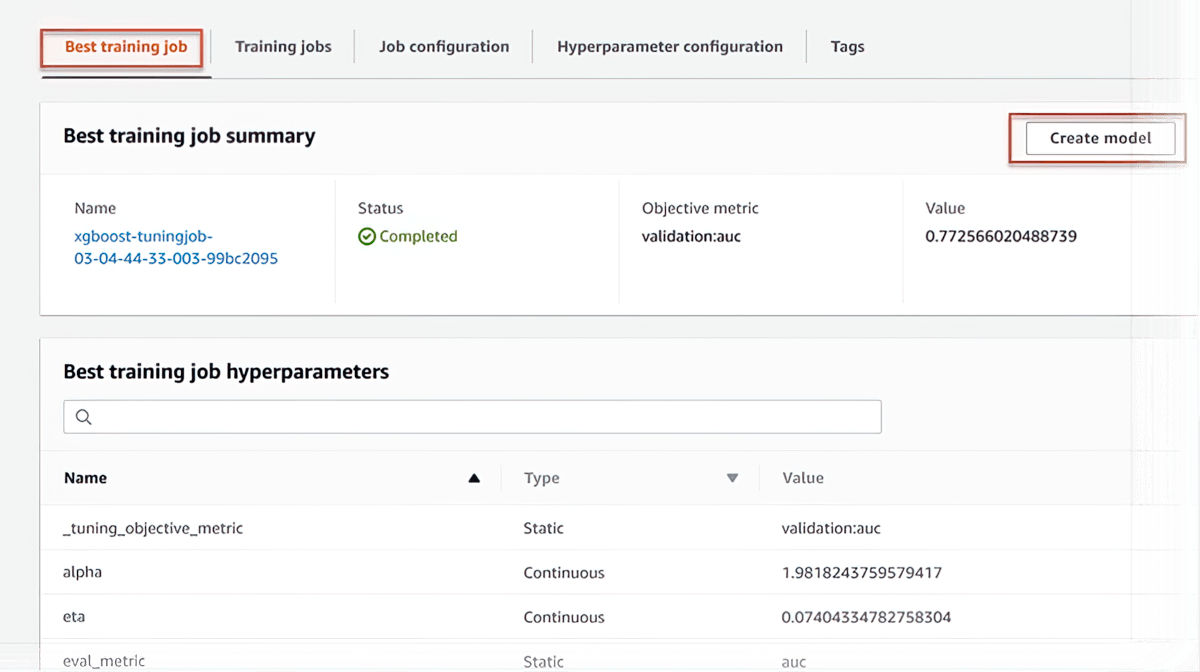
托管型 Spot 训练
SageMaker AI 可在计算容量可用时自动运行训练作业,从而帮助将训练成本降低多达 90%。这些训练工作还可以抵御容量变化造成的中断。
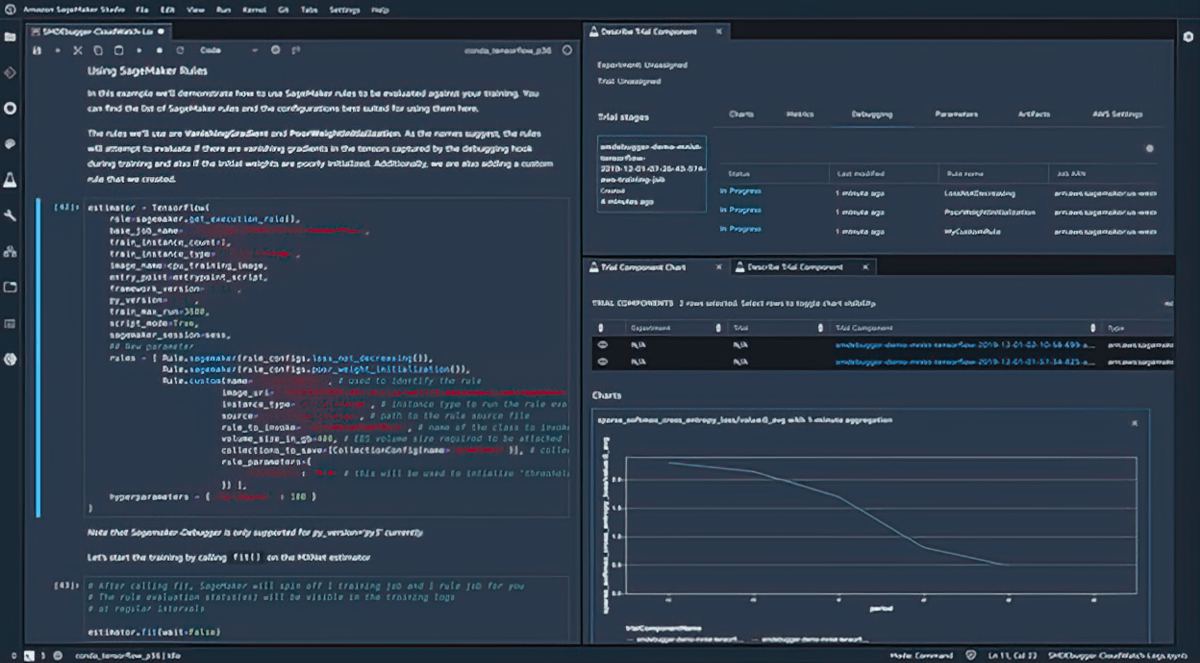
调试
Amazon SageMaker Debugger 会实时捕获指标并分析训练作业,因此您可以在将模型部署到生产前快速纠正性能问题。您还可以通过访问底层训练容器,远程连接到 SageMaker 中的模型训练环境进行调试。
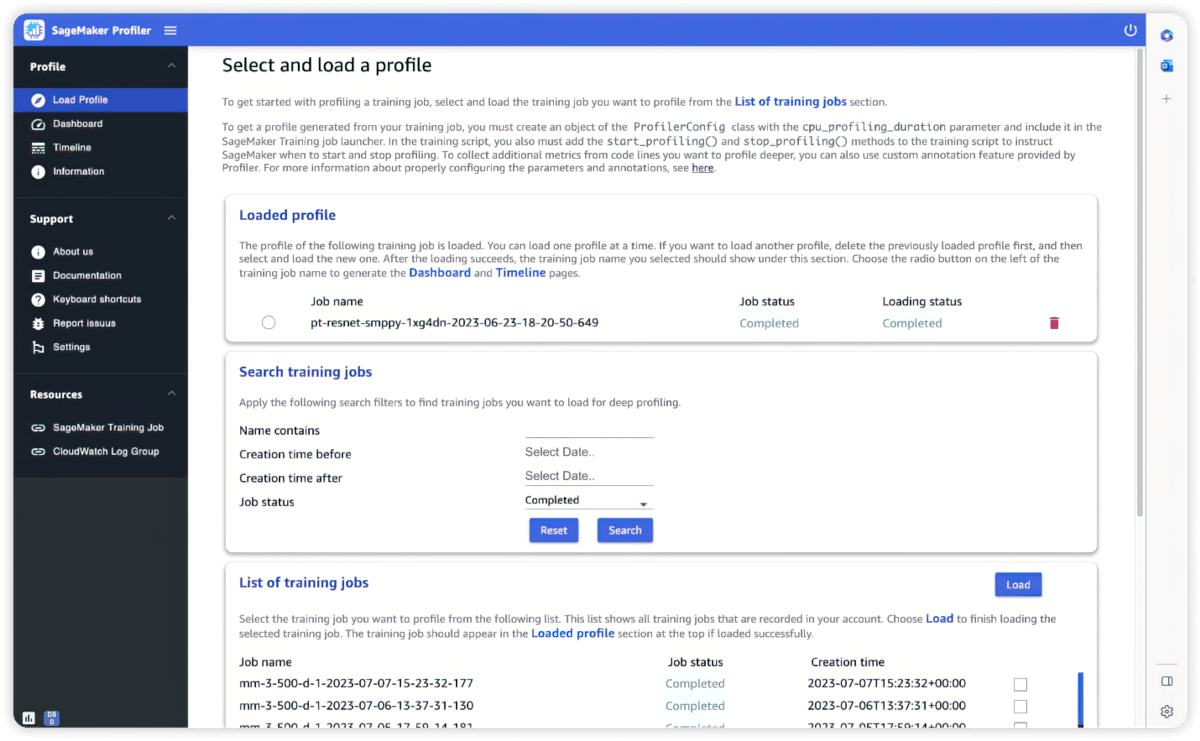
分析工具
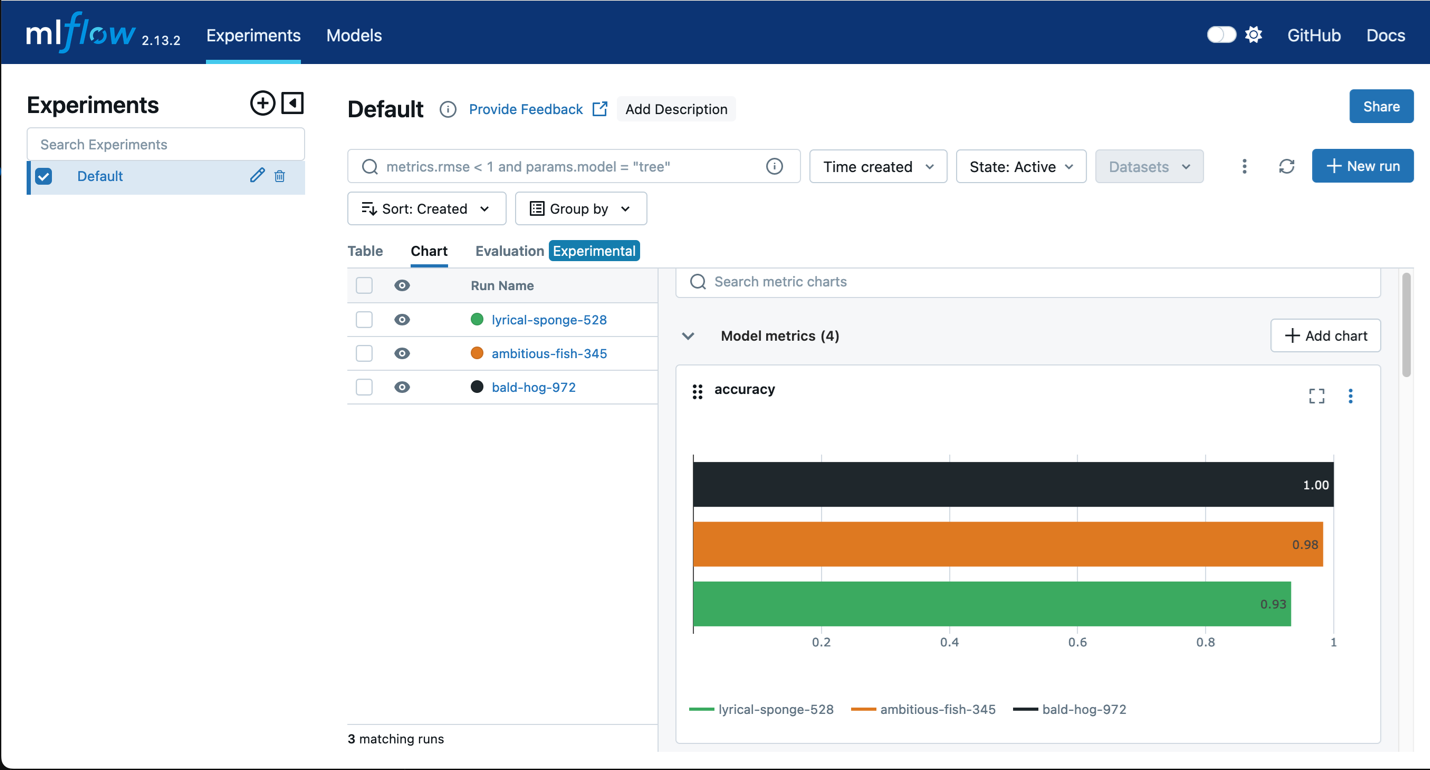
灵活且更快的训练
完全自定义
SageMaker AI 自带内置库和工具,让模型训练变得更容易、更快捷。SageMaker AI 适用于常用的开源机器学习模型(例如 GPT、BERT 和 DALL·E)、机器学习框架(例如 PyTorch 和 TensorFlow)和转换器(例如 Hugging Face)。借助 SageMaker AI,您可以根据自己的需求使用常用的开源库和工具,例如 DeepSpeed、Megatron、Horovod、Ray Tune 和 TensorBoard。
本地代码转换
Amazon SageMaker Python SDK 可以帮助您在首选的集成式开发环境(IDE)和本地笔记本中编写 ML 代码,并将其与运行时依赖项一起作为大规模 ML 模型训练作业运行,而无需进行大量代码更改。您只需要向本地机器学习代码添加一行代码(Python 装饰器)。SageMaker Python SDK 将代码与数据集和工作区环境设置配合使用,并将其作为 SageMaker 训练作业运行。
自动化机器学习训练工作流
自动化训练工作流使用 Amazon SageMaker Pipelines,可帮助您创建可重复的流程,以针对快速试验和模型再训练编排模型开发步骤。您可以定期或在某些事件启动时自动运行步骤,也可以根据需要手动运行这些步骤。
灵活的训练计划
为了满足您的训练时间表和预算,SageMaker AI 可帮助您制定最经济高效的训练计划,这些计划可使用来自多个计算容量块的计算资源。批准这些训练计划后,SageMaker AI 就会自动配置基础设施,并在这些计算资源上运行训练作业,而不需要任何手动干预,从而节省数周管理培训流程的工作量,让作业与计算可用性保持一致。