AWS Machine Learning Blog
Category: PyTorch on AWS

Accelerated PyTorch inference with torch.compile on AWS Graviton processors
Originally PyTorch used an eager mode where each PyTorch operation that forms the model is run independently as soon as it’s reached. PyTorch 2.0 introduced torch.compile to speed up PyTorch code over the default eager mode. In contrast to eager mode, the torch.compile pre-compiles the entire model into a single graph in a manner that’s optimal for […]
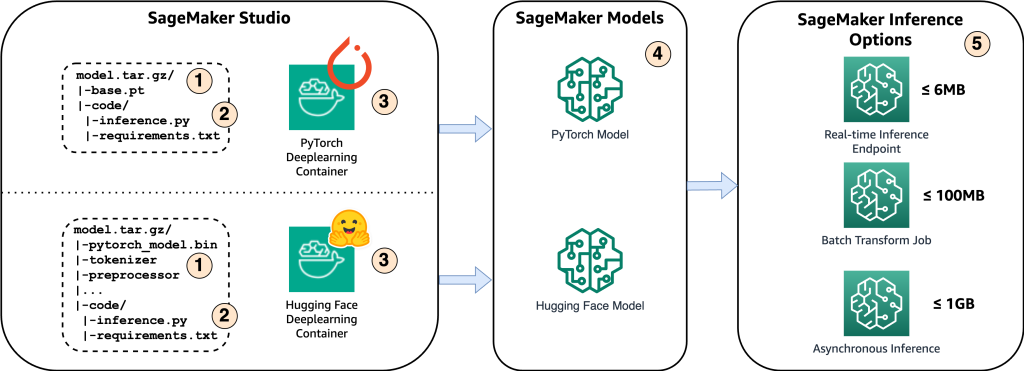
Host the Whisper Model on Amazon SageMaker: exploring inference options
OpenAI Whisper is an advanced automatic speech recognition (ASR) model with an MIT license. ASR technology finds utility in transcription services, voice assistants, and enhancing accessibility for individuals with hearing impairments. This state-of-the-art model is trained on a vast and diverse dataset of multilingual and multitask supervised data collected from the web. Its high accuracy […]

Enable faster training with Amazon SageMaker data parallel library
Large language model (LLM) training has become increasingly popular over the last year with the release of several publicly available models such as Llama2, Falcon, and StarCoder. Customers are now training LLMs of unprecedented size ranging from 1 billion to over 175 billion parameters. Training these LLMs requires significant compute resources and time as hundreds […]

Optimize AWS Inferentia utilization with FastAPI and PyTorch models on Amazon EC2 Inf1 & Inf2 instances
When deploying Deep Learning models at scale, it is crucial to effectively utilize the underlying hardware to maximize performance and cost benefits. For production workloads requiring high throughput and low latency, the selection of the Amazon Elastic Compute Cloud (EC2) instance, model serving stack, and deployment architecture is very important. Inefficient architecture can lead to […]

Fine-tune GPT-J using an Amazon SageMaker Hugging Face estimator and the model parallel library
GPT-J is an open-source 6-billion-parameter model released by Eleuther AI. The model is trained on the Pile and can perform various tasks in language processing. It can support a wide variety of use cases, including text classification, token classification, text generation, question and answering, entity extraction, summarization, sentiment analysis, and many more. GPT-J is a […]

Host ML models on Amazon SageMaker using Triton: CV model with PyTorch backend
PyTorch is a machine learning (ML) framework based on the Torch library, used for applications such as computer vision and natural language processing. One of the primary reasons that customers are choosing a PyTorch framework is its simplicity and the fact that it’s designed and assembled to work with Python. PyTorch supports dynamic computational graphs, […]

Optimized PyTorch 2.0 inference with AWS Graviton processors
New generations of CPUs offer a significant performance improvement in machine learning (ML) inference due to specialized built-in instructions. Combined with their flexibility, high speed of development, and low operating cost, these general-purpose processors offer an alternative to other existing hardware solutions. AWS, Arm, Meta and others helped optimize the performance of PyTorch 2.0 inference […]

Build a GNN-based real-time fraud detection solution using the Deep Graph Library without using external graph storage
Fraud detection is an important problem that has applications in financial services, social media, ecommerce, gaming, and other industries. This post presents an implementation of a fraud detection solution using the Relational Graph Convolutional Network (RGCN) model to predict the probability that a transaction is fraudulent through both the transductive and inductive inference modes. You can deploy our implementation to an Amazon SageMaker endpoint as a real-time fraud detection solution, without requiring external graph storage or orchestration, thereby significantly reducing the deployment cost of the model.

Reduce deep learning training time and cost with MosaicML Composer on AWS
In the past decade, we have seen Deep learning (DL) science adopted at a tremendous pace by AWS customers. The plentiful and jointly trained parameters of DL models have a large representational capacity that brought improvements in numerous customer use cases, including image and speech analysis, natural language processing (NLP), time series processing, and more. […]

Build flexible and scalable distributed training architectures using Kubeflow on AWS and Amazon SageMaker
In this post, we demonstrate how Kubeflow on AWS (an AWS-specific distribution of Kubeflow) used with AWS Deep Learning Containers and Amazon Elastic File System (Amazon EFS) simplifies collaboration and provides flexibility in training deep learning models at scale on both Amazon Elastic Kubernetes Service (Amazon EKS) and Amazon SageMaker utilizing a hybrid architecture approach. […]